Python se ha ganado una reputación por su versatilidad y la inclusión de muchas herramientas, lo que lo convierte en el lenguaje elegido para la ciencia de datos. Animó a muchas bibliotecas a innovar en este campo. Para mejorar sus habilidades y explorar nuevas oportunidades, es importante mantenerse actualizado con las herramientas emergentes y recientemente desarrolladas.
La ciencia de datos se ha convertido en un campo cada vez más importante en los últimos años, en parte porque hay nuevas y poderosas herramientas disponibles que facilitan que las personas recopilen y analicen datos. Hay muchas herramientas de ciencia de datos disponibles en Python, que se pueden usar para realizar una variedad de tareas, incluida la creación de gráficos, predicciones y visualizaciones prospectivas. Verificar Maneras de estar al tanto de las últimas tendencias en ciencia de datos.

1. ConnectorX: Simplifique la carga de datos
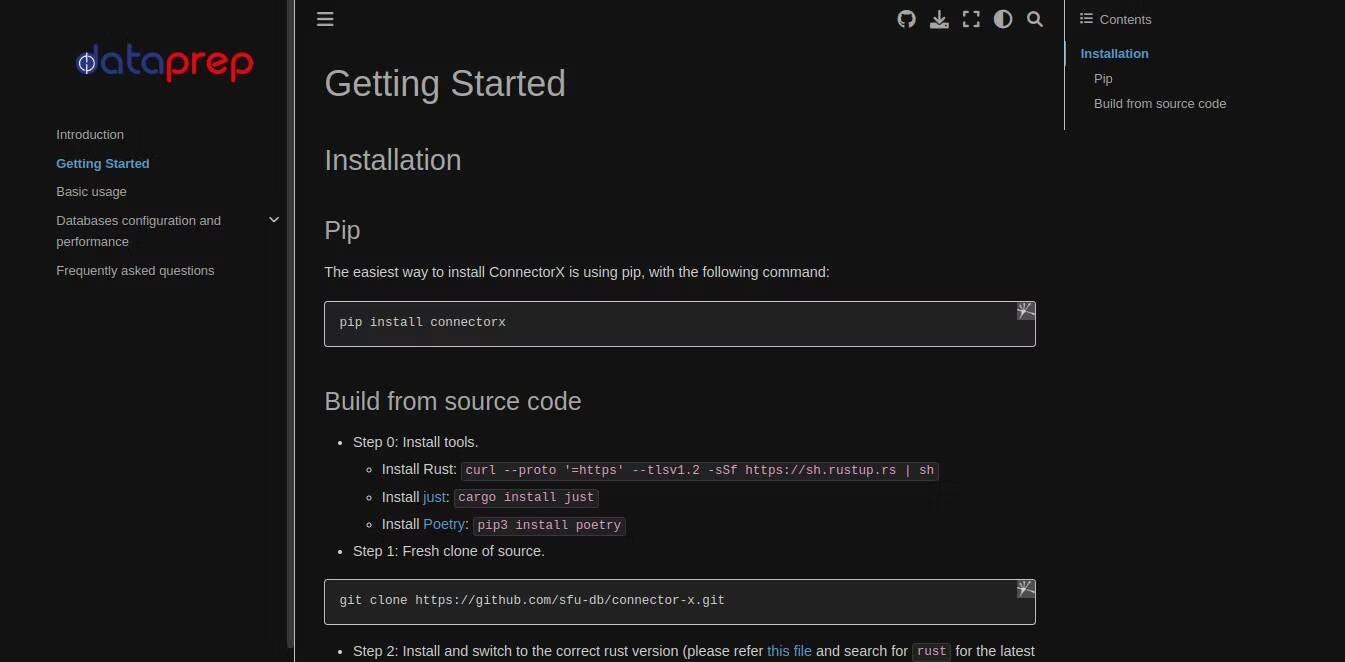
Si bien la mayoría de los datos residen en bases de datos, los cálculos generalmente ocurren fuera de ellas. Sin embargo, mover datos hacia y desde las bases de datos durante el trabajo real puede causar ralentizaciones.
levantarse ConectorX Carga datos de bases de datos en muchas herramientas populares de análisis de datos en Python y mantiene las cosas rápidas y fluidas al reducir la cantidad de trabajo que se debe realizar.
ConnectorX utiliza la biblioteca del lenguaje de programación Rust en su núcleo. Esto permite mejoras como la capacidad de cargar desde la fuente de datos en paralelo con la partición. Los datos en una base de datos PostgreSQL, por ejemplo, puede cargarlos de esta manera especificando la columna de la sección.
IConnectorX también admite la lectura de datos de varias bases de datos, incluidas MySQL/MariaDB, SQLite, Amazon Redshift, Microsoft SQL Server, Azure SQL y Oracle.
Puede convertir los resultados a Pandas o PyArrow DataFrames, o reenviarlos a Modin, Dask o Polars usando PyArrow.
2. DuckDB: habilite las cargas de trabajo de consultas de análisis
Usado PatoDB Almacena datos verticales y optimiza las cargas de trabajo de consultas de análisis de ejecución prolongada. Proporciona todas las funciones que esperaría de una base de datos tradicional, incluidas las transacciones ACID.
Además, puede configurarlo en un entorno de Python con un comando instalación de pip Uno, eliminando la necesidad de configurar un conjunto de aplicaciones separado.
DuckDB ingiere datos en formato CSV, JSON o Parquet. DuckDB mejora la eficiencia al dividir las bases de datos resultantes en archivos físicos separados según claves como el año y el mes.
Cuando se utiliza DuckDB para realizar consultas, se comporta como una base de datos relacional normal basada en SQL, pero con características adicionales, como el muestreo aleatorio de datos y la generación de funciones analíticas (función de marco).
Además, DuckDB proporciona formatos útiles como búsqueda de texto completo, importación/exportación de Excel, conexiones directas a SQLite y PostgreSQL, exportación de archivos Parquet y soporte para muchos tipos y formatos de datos geoespaciales populares. Verificar ¿Cómo funcionan las tablas temporales de SQL Server?.
3. Optimus: simplificar el procesamiento de datos

Limpiar y preparar datos para proyectos centrados en DataFrame puede ser una tarea estresante que requiere mucha eficiencia. Optimus Es un conjunto de herramientas completo diseñado para cargar, explorar, limpiar y reescribir datos en varias fuentes de datos.
Optimus puede usar Pandas, Dask, CUDF (y Dask + CUDF), Vaex o Spark como motor de datos principal. Puede cargar y guardar en Arrow, Parquet, Excel y varias fuentes de bases de datos populares, o formatos de archivo planos como CSV y JSON.
Similar a la API de procesamiento de datos de Optimus Pandas, pero proporciona más conectores .filas() و columnas(). Estos conectores facilitan mucho la realización de diversas tareas.
Por ejemplo, puede ordenar o filtrar el marco de administración de datos en función de los valores de las columnas, cambiar los datos utilizando criterios específicos o limitar las operaciones en función de determinadas condiciones. Además, Optimus incluye asistentes diseñados para manejar tipos de datos comunes del mundo real, como direcciones de correo electrónico y URL.
Es importante darse cuenta de que Optimus se encuentra actualmente en desarrollo activo y su último lanzamiento oficial fue en 2020. Como resultado, puede estar menos actualizado en comparación con otros componentes de su colección. Verificar Aprenda análisis de datos de forma gratuita: los mejores sitios web.
4. Polars: marco de gestión acelerada de datos

Si se encuentra trabajando con marcos de gestión de datos y está frustrado con las limitaciones de rendimiento de Pandas, Polares Es una excelente solución. Esta biblioteca de marco de datos para Python proporciona una sintaxis conveniente como Pandas.
A diferencia de Pandas, Polars usa una biblioteca escrita en Rust que amplía las capacidades de su dispositivo. No necesita usar una sintaxis especial para disfrutar de funciones que mejoran el rendimiento, como el procesamiento en paralelo o SIMD.
Incluso las operaciones simples como leer un archivo CSV son más rápidas. Además, Polars proporciona modos de ejecución avanzados y completos, lo que permite la ejecución inmediata de consultas o el aplazamiento según sea necesario.
También proporciona una API de transmisión para manejar consultas incrementales, aunque es posible que esta función aún no esté disponible para todas las funciones. Los desarrolladores de Rust también pueden crear sus propios complementos Polars usando pyo3.
5. Snakemake: Automatice los flujos de trabajo de ciencia de datos

Configurar flujos de trabajo de ciencia de datos presenta muchos desafíos diversos, y garantizar la coherencia y la previsibilidad puede ser más desafiante. El trata Serpiente Esta limitación se debe a la automatización de la configuración de análisis de datos en Python, lo que garantiza resultados uniformes para todos.
Muchos de los proyectos de ciencia de datos actuales se basan en Snakemake. A medida que los flujos de trabajo de la ciencia de datos se vuelven cada vez más complejos, resulta útil automatizarlos con Snakemake.
El flujo de trabajo de Snakemake es similar al de GNU. Puede especificar los resultados deseados mediante reglas que definen la entrada, la salida y los comandos necesarios. Puede crear reglas de flujo de trabajo multiproceso para aprovechar el procesamiento paralelo.
Además, los datos de configuración pueden originarse a partir de archivos JSON/YAML. Los flujos de trabajo también le permiten definir funciones para transformar los datos utilizados en las reglas y registrar las acciones realizadas en cada paso.
Snakemake diseña trabajos para que sean portátiles e implementables en entornos administrados por Kubernetes o plataformas en la nube seleccionadas, como Google Cloud Life Sciences o Tibanna en AWS.
Puede congelar los flujos de trabajo para usar un conjunto granular de paquetes, y la ejecución de los flujos de trabajo puede almacenar las pruebas unitarias creadas con ellos. Para el archivado de formato largo, puede almacenar flujos de trabajo como archivos zip. Verificar Ética de datos: el código de conducta que todo científico de datos debe seguir.
Herramientas de ciencia de datos incomparables para Python
Al adoptar estas últimas herramientas de ciencia de datos, puede aumentar su productividad, ampliar sus capacidades y embarcarse en emocionantes viajes basados en datos. Sin embargo, recuerde que el panorama de la ciencia de datos está evolucionando. Para mantenerse a la vanguardia, siga explorando, experimentando y adaptándose a las nuevas herramientas y tecnologías que están surgiendo en este campo cambiante. Puedes ver ahora Cómo convertirse en un especialista en entrada de datos.