أصبح تحليل البيانات والنصوص أمرًا أساسيًا من أجل فهم السياق واستخراج المعلومات القيمة من مُختلف المعلومات المُتاحة. واحدة من أدوات التحليل المُتقدمة والتي تجذب اهتمام العديد من الباحثين والمحللين هي Scikit-LLM. تسمح هذه الأداة بتحليل النصوص باستخدام نماذج اللغات الكبيرة، مما يُسهِّل استخراج الأنماط والمعلومات الهامة من النصوص بشكل فعَّال.
Scikit-LLM عبارة عن حزمة Python تُساعد على دمج نماذج اللغات الكبيرة (LLMs) في إطار عمل Scikit-Learn. والذي يُساعد في إنجاز مهام تحليل النص. إذا كنت مُعتادًا على Scikit-Learn، فسيكون من الأسهل عليك العمل مع Scikit-LLM.
من المهم ملاحظة أنَّ Scikit-LLM لا يحل محل Scikit-Learn. حيث أنَّ Scikit-Learn هي مكتبة لتعلم الآلة ذات الأغراض العامة ولكن Scikit-LLM مُصممة خصيصًا لمهام تحليل النص.
سنقوم في هذه المقالة باستكشاف كيفية استخدام Scikit-LLM لتحليل النصوص وكيف يُمكن أن تُساعدك هذه الأداة في فهم مضامين النصوص بطريقة مُتقدمة. تحقق من أفضل مكتبات تعلم الآلة لكسب خبرة إضافية.

الشروع في العمل باستخدام Scikit-LLM
للبدء في استخدام Scikit-LLM، ستحتاج إلى تثبيت المكتبة وتكوين مفتاح API الخاص بك. لتثبيت المكتبة، افتح IDE التي تُفضلها وقم بإنشاء بيئة افتراضية جديدة. سيساعد هذا في منع أي تعارضات مُحتملة في إصدار المكتبة. ثم قم بتشغيل الأمر التالي في Terminal.
pip install scikit-llm سيقوم هذا الأمر بتثبيت Scikit-LLM وتبعياتها المطلوبة.
لتكوين مفتاح API الخاص بك، تحتاج إلى الحصول عليه من مُزوِّد LLM الذي ترغب في الاعتماد عليه. للحصول على مفتاح OpenAI API، اتبع الخطوات التالية:
انتقل إلى صفحة OpenAI API. ثم انقر فوق ملفك الشخصي الموجود في الزاوية العلوية من النافذة. حدد عرض مفاتيح API. سينقلك هذا إلى صفحة مفاتيح API.
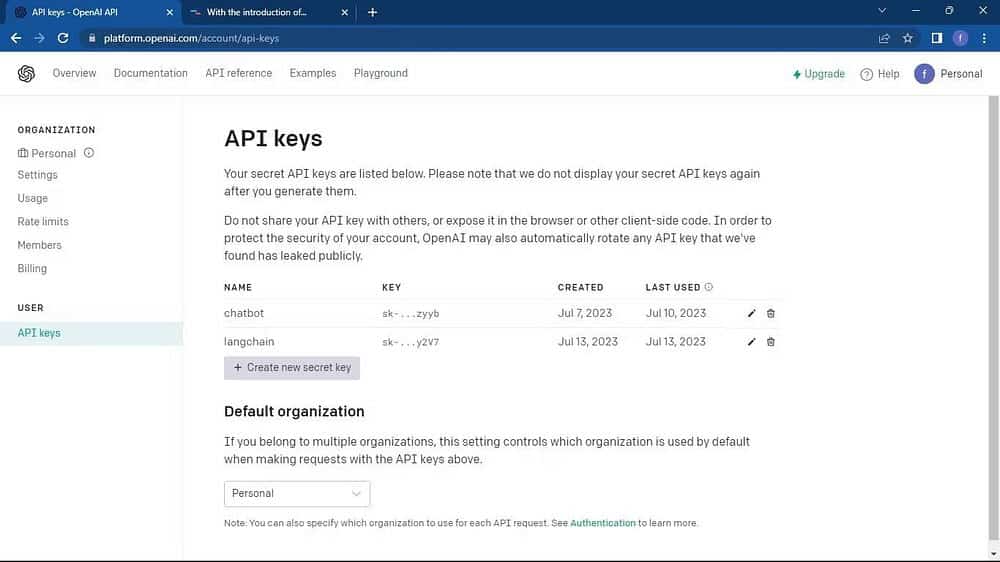
في صفحة مفاتيح API، انقر فوق الزر إنشاء مفتاح سري جديد.
قم بتسمية مفتاح API الخاص بك وانقر فوق الزر “إنشاء مفتاح سري” لإنشاء المفتاح. بعد الإنشاء، ستحتاج إلى نسخ المفتاح وتخزينه في مكان آمن لأنَّ OpenAI لن تعرض المفتاح مرة أخرى. إذا فقدته، سوف تحتاج إلى إنشاء واحد جديد.
ملاحظة: كود المصدر الكامل مُتاح في مستودع GitHub.
الآن بعد أن أصبح لديك مفتاح API، افتح IDE وقم باستيراد فئة SKLLMConfig من مكتبة Scikit-LLM. تُتيح لك هذه الفئة (Class) ضبط خيارات التكوين المتعلقة باستخدام نماذج اللغات الكبيرة.
from skllm.config import SKLLMConfig تتوقع منك هذه الفئة تعيين مفتاح OpenAI API وتفاصيل المؤسسة.
# Set your OpenAI API key
SKLLMConfig.set_openai_key("Your API key")
# Set your OpenAI organization
SKLLMConfig.set_openai_org("Your organization ID") مُعرف المُؤسسة والاسم ليسا نفس الشيء. مُعرِّف المؤسسة هو معرف فريد لمؤسستك. للحصول على معرف مؤسستك، انتقل إلى صفحة إعدادات مؤسسة OpenAI وانسخه. لقد قمت الآن بإنشاء اتصال بين Scikit-LLM ونموذج اللغة الكبير.
ملاحظة: تتطلب Scikit-LLM أن يكون لديك خطة الدفع أولاً بأول. وذلك لأنَّ حساب OpenAI التجريبي المجاني له حد أقصى لمعدل الإدخال يبلغ ثلاثة طلبات في الدقيقة، وهو ما لا يكفي لـ Scikit-LLM.
ستؤدي محاولة استخدام الحساب التجريبي المجاني إلى حدوث خطأ مشابه للخطأ الموضح أدناه أثناء إجراء تحليل النص. تحقق من ما هو حد الرمز المُميز لـ ChatGPT وهل يُمكنك تجاوزه؟

لمعرفة المزيد عن حدود المعدل. انتقل إلى صفحة حدود مُعدل OpenAI.
ملاحظة: لا يقتصر مُزوِّد LLM على OpenAI فقط. يمكنك أيضًا استخدام مُزوِّدي LLM الآخرين. تحقق من مُقارنة بين Claude و ChatGPT: أيّ LLM هو الأفضل للمهام اليومية؟
استيراد المكتبات المطلوبة وتحميل مجموعة البيانات
قم باستيراد دالة pandas التي ستستخدمها لتحميل مجموعة البيانات. أيضًا، من Scikit-LLM و scikit-learn، قم باستيراد الفئات المطلوبة.
import pandas as pd
from skllm import ZeroShotGPTClassifier, MultiLabelZeroShotGPTClassifier
from skllm.preprocessing import GPTSummarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MultiLabelBinarizer بعد ذلك، قم بتحميل مجموعة البيانات التي تُريد إجراء تحليل النص عليها. يستخدم هذا الكود مجموعة بيانات أفلام IMDB. ومع ذلك، يُمكنك تعديله لاستخدام مجموعة البيانات التي تُفضلها.
# Load your dataset
data = pd.read_csv("imdb_movies_dataset.csv")
# Extract the first 100 rows
data = data.head(100) إنَّ استخدام أول 100 صف فقط من مجموعة البيانات ليس إلزاميًا. يُمكنك استخدام مجموعة البيانات بأكملها.
بعد ذلك، قم باستخراج الميزات وأعمدة التسمية. ثم قم بتقسيم مجموعة بياناتك إلى مجموعات تدريب واختبار.
# Extract relevant columns
X = data['Description']
# Assuming 'Genre' contains the labels for classification
y = data['Genre']
# Split the dataset into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) يحتوي عمود Genre على التصنيفات التي تُريد التنبؤ بها.
تصنيف النص بدون لقطة باستخدام Scikit-LLM
يُعد تصنيف النص بدون لقطة ميزة تقدمها نماذج اللغات الكبيرة. فهو يُصنف النص إلى فئات مُحددة مسبقًا دون الحاجة إلى تدريب واضح على البيانات المصنفة. تعد هذه الإمكانية مفيدة للغاية عند التعامل مع المهام التي تحتاج فيها إلى تصنيف النص إلى فئات لم تتوقعها أثناء التدريب على النموذج.
لإجراء تصنيف نصي بدون لقطات باستخدام Scikit-LLM، استخدم فئة ZeroShotGPTClassifier.
# Perform Zero-Shot Text Classification
zero_shot_clf = ZeroShotGPTClassifier(openai_model="gpt-3.5-turbo")
zero_shot_clf.fit(X_train, y_train)
zero_shot_predictions = zero_shot_clf.predict(X_test)
# Print Zero-Shot Text Classification Report
print("Zero-Shot Text Classification Report:")
print(classification_report(y_test, zero_shot_predictions)) سيكون الإخراج كما يلي:
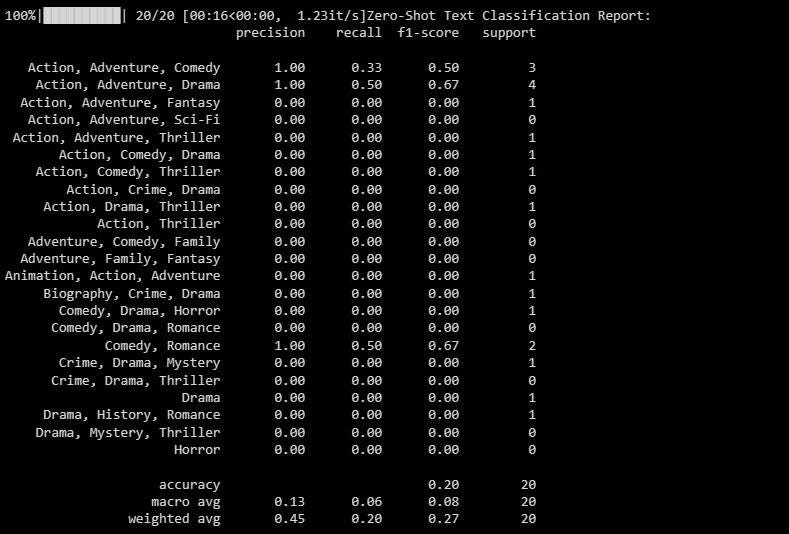
يُوفر تقرير التصنيف مقاييس لكل تصنيف يحاول النموذج التنبؤ به.
تصنيف نص مُتعدد التسميات بدون لقطة باستخدام Scikit-LLM
في بعض السيناريوهات، قد ينتمي نص واحد إلى فئات مُتعددة في وقت واحد. نماذج التصنيف التقليدية تُكافح من أجل إتمام المُهمة. من ناحية أخرى، فإنَّ Scikit-LLM يجعل هذا التصنيف مُمكنًا. يعد تصنيف النص ذو التسميات الصفرية المُتعددة أمرًا بالغ الأهمية في تعيين تسميات وصفية متعددة لعينة نصية واحدة.
استخدم MultiLabelZeroShotGPTClassifier للتنبؤ بالتصنيفات المُناسبة لكل عينة نصية.
# Perform Multi-Label Zero-Shot Text Classification
# Make sure to provide a list of candidate labels
candidate_labels = ["Action", "Comedy", "Drama", "Horror", "Sci-Fi"]
multi_label_zero_shot_clf = MultiLabelZeroShotGPTClassifier(max_labels=2)
multi_label_zero_shot_clf.fit(X_train, candidate_labels)
multi_label_zero_shot_predictions = multi_label_zero_shot_clf.predict(X_test)
# Convert the labels to binary array format using MultiLabelBinarizer
mlb = MultiLabelBinarizer()
y_test_binary = mlb.fit_transform(y_test)
multi_label_zero_shot_predictions_binary = mlb.transform(multi_label_zero_shot_predictions)
# Print Multi-Label Zero-Shot Text Classification Report
print("Multi-Label Zero-Shot Text Classification Report:")
print(classification_report(y_test_binary, multi_label_zero_shot_predictions_binary)) في الكود أعلاه، يُمكنك تحديد التسميات التي تم تصفيتها والتي قد ينتمي إليها النص الخاص بك.
الإخراج كما هو موضح أدناه:
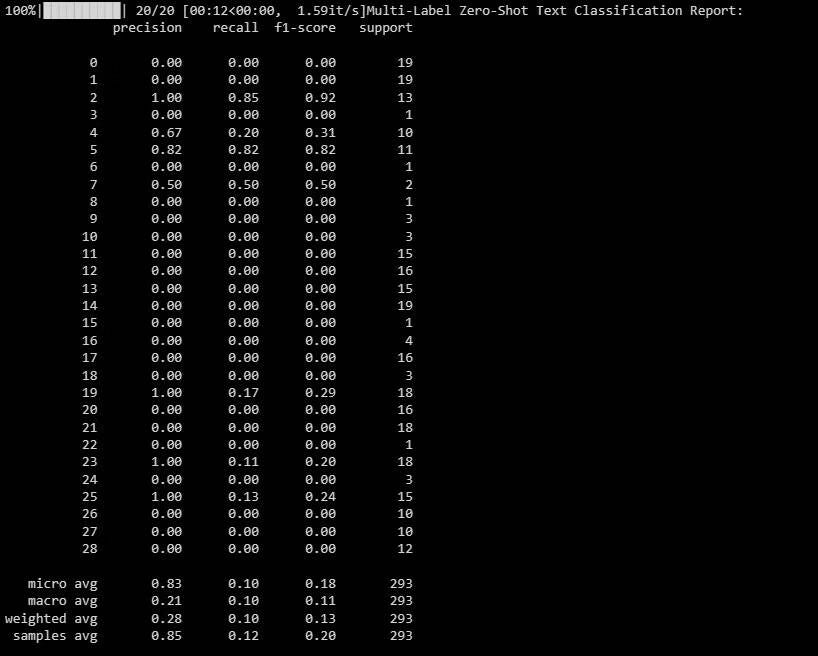
يُساعدك هذا التقرير على فهم مدى جودة أداء نموذجك لكل تصنيف في التصنيف متعدد التسميات.
توجيه النص باستخدام Scikit-LLM
في توجيه النص، يتم تحويل البيانات النصية إلى تنسيق رقمي يُمكن لنماذج تعلم الآلة فهمه. تُقدم Scikit-LLM دالة GPTectorizer لهذا الغرض. تسمح لك بتحويل النص إلى متجهات ذات أبعاد ثابتة باستخدام نماذج GPT.
يُمكنك تحقيق ذلك باستخدام تردد المصطلح — تردد المستند العكسي.
# Perform Text Vectorization using TF-IDF
tfidf_vectorizer = TfidfVectorizer(max_features=1000)
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
X_test_tfidf = tfidf_vectorizer.transform(X_test)
# Print the TF-IDF vectorized features for the first few samples
print("TF-IDF Vectorized Features (First 5 samples):")
print(X_train_tfidf[:5]) # Change to X_test_tfidf if you want to print the test set هنا هو الإخراج:
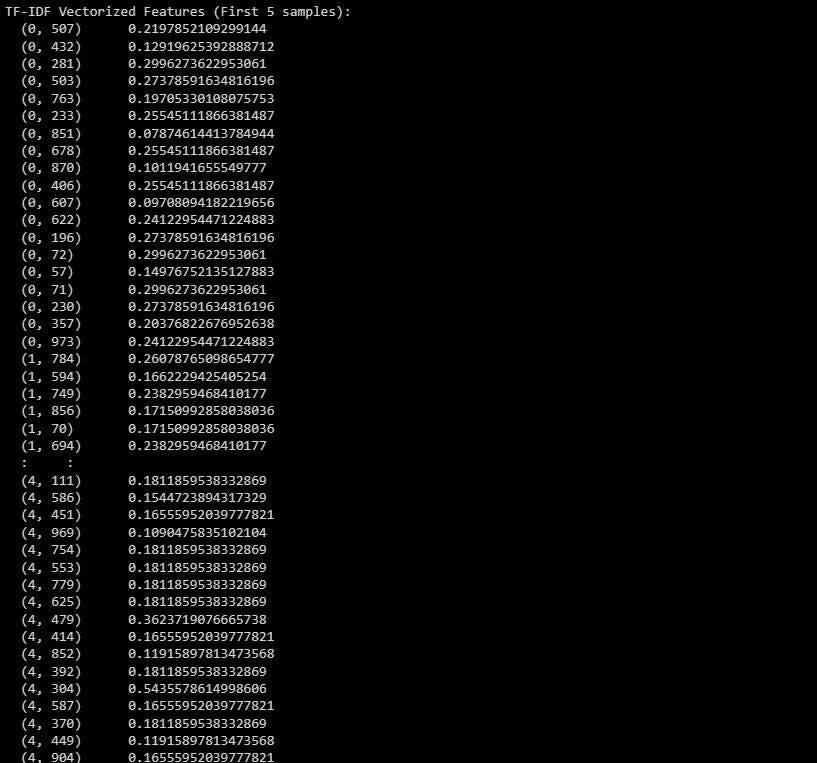
يُمثل الإخراج ميزات TF-IDF الموجهة للعينات الخمس الأولى في مجموعة البيانات. تحقق من إضافات Chrome المدعومة بالذكاء الاصطناعي لتلخيص فيديوهات YouTube.
تلخيص النص باستخدام Scikit-LLM
يُساعد تلخيص النص في تكثيف جزء من النص مع الحفاظ على معلوماته الأكثر أهمية. تُقدم Scikit-LLM دالة GPTSummarizer، التي تستخدم نماذج GPT لإنشاء مُلخصات موجزة للنص.
# Perform Text Summarization
summarizer = GPTSummarizer(openai_model="gpt-3.5-turbo", max_words=15)
summaries = summarizer.fit_transform(X_test)
print(summaries) الإخراج هو كما يلي:
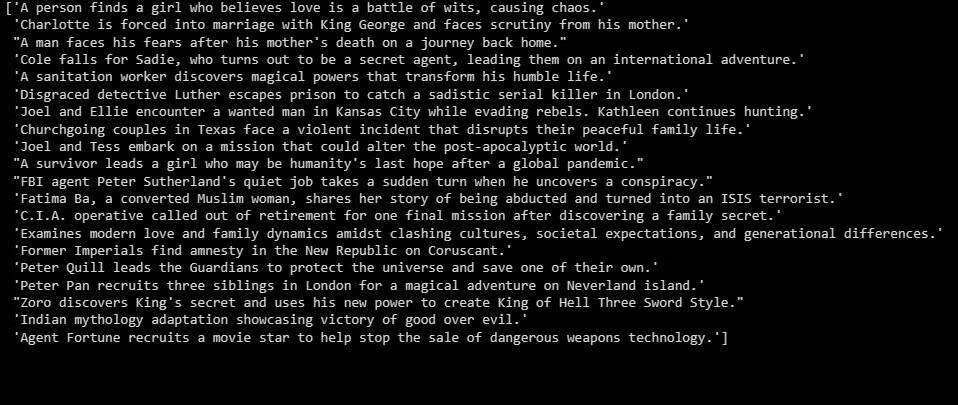
ما ورد أعلاه هو ملخص للبيانات التي تم تحديدها.
الأسئلة الشائعة
س1. ما هي Scikit-LLM وماذا تعني نماذج اللغات الكبيرة؟
Scikit-LLM هي مكتبة برمجية تستخدم لتحليل النصوص باستخدام نماذج اللغات الكبيرة (LLM)، والتي هي نماذج تم تدريبها على مجموعات كبيرة من البيانات اللغوية. تُتيح لنا هذه النماذج فهم اللغة والمعاني المُختلفة المُحتملة للكلمات والجمل والنصوص.
س2. ما هي استخدامات Scikit-LLM؟
يُمكن استخدام Scikit-LLM في العديد من التطبيقات، مثل تصنيف النصوص إلى فئات مُختلفة، واستخراج الكلمات الرئيسية من النصوص، واكتشاف العلاقات اللغوية بين الكلمات، وتوليف نصوص جديدة استنادًا إلى النصوص القائمة.
س3. هل يتعين علي أن أكون مبرمجًا مُحترفًا لاستخدام Scikit-LLM؟
لا بالضرورة. يُمكن لأي شخص مُهتم بتحليل النصوص أن يتعلم استخدام Scikit-LLM بسهولة. ومع ذلك، فإنَّ أي خلفية في البرمجة وفهم أساسيات اللغة الطبيعية ستكون مُفيدة.
س4. هل يتوجب علي استخدام بيانات ضخمة لتدريب نماذج Scikit-LLM؟
نعم، يتطلب تدريب نماذج Scikit-LLM استخدام مجموعات بيانات كبيرة عادة. ولكن يمكن استخدام نماذج جاهزة تم تدريبها مسبقًا بواسطة الأشخاص والمؤسسات لتحليل النصوص.
س5. ما هي اللغات التي يمكن أن تُدرب عليها نماذج Scikit-LLM؟
يمكن تدريب نماذج Scikit-LLM على العديد من اللغات المُختلفة، بما في ذلك الإنجليزية والإسبانية والصينية والعربية وغيرها. توجد نماذج جاهزة للعديد من اللغات الشائعة. تحقق من كيفية إنشاء مثيل ChatGPT مُخصص ببياناتك الخاصة.
بناء التطبيقات بالإعتماد على نماذج LLM
تفتح Scikit-LLM عالمًا من الإمكانيات لتحليل النصوص باستخدام النماذج اللغوية الكبيرة. يُعد فهم التكنولوجيا الكامنة وراء نماذج اللغات الكبيرة أمرًا بالغ الأهمية. سيساعدك ذلك على فهم نقاط القوة والضعف لديها والتي يُمكن أن تُساعدك في بناء تطبيقات فعالة على رأس هذه التكنولوجيا المُتطورة. يُمكنك الإطلاع الآن على تحسين تجربة استخدام ChatGPT من خلال إنشاء شخصيات مُستخدم مُخصصة.