Анализ данных и текста стал необходим для понимания контекста и извлечения ценной информации из различной доступной информации. Одним из передовых инструментов анализа, вызывающим интерес многих исследователей и аналитиков, является Scikit-LLM. Этот инструмент позволяет анализировать текст с использованием больших языковых моделей, что упрощает эффективное извлечение важных шаблонов и информации из текстов.
Scikit-LLM — это пакет Python, который помогает интегрировать большие языковые модели (LLM) в среду Scikit-Learn. Что помогает в выполнении задач по анализу текста. Если вы знакомы с Scikit-Learn, вам будет проще работать с Scikit-LLM.
Важно отметить, что Scikit-LLM не заменяет Scikit-Learn. Scikit-Learn — это библиотека машинного обучения общего назначения, Scikit-LLM специально разработана для задач анализа текста.
В этой статье мы рассмотрим, как использовать Scikit-LLM для анализа текста и как этот инструмент может помочь вам глубже понять текстовый контент. Проверять Лучшие библиотеки машинного обучения для получения дополнительного опыта.

Начало работы с Scikit-LLM
Чтобы начать использовать Scikit-LLMвам нужно будет установить библиотеку и настроить ключ API. Чтобы установить библиотеку, откройте предпочитаемую вами среду IDE и создайте новую виртуальную среду. Это поможет предотвратить потенциальные конфликты версий библиотеки. Затем выполните следующую команду в Терминале.
pip install scikit-llm Эта команда установит Scikit-LLM и необходимые зависимости.
Чтобы настроить собственный ключ API, вам необходимо получить его у поставщика LLM, на которого вы хотите положиться. Чтобы получить ключ OpenAI API, выполните следующие действия:
Перейти к Страница API OpenAI. Затем нажмите на свой профиль, расположенный в верхнем углу окна. Найдите Просмотр ключей API. Вы попадете на страницу ключей API.
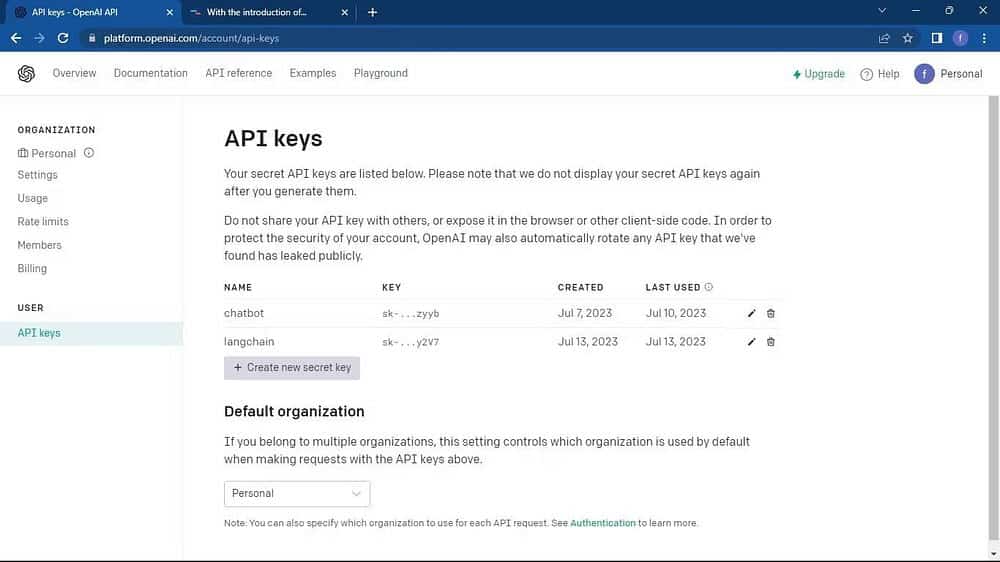
На странице Ключи API нажмите кнопку Создать новый секретный ключ.
Назовите свой ключ API и нажмите кнопку «Создать секретный ключ», чтобы сгенерировать ключ. После генерации вам нужно будет скопировать ключ и сохранить его в безопасном месте, поскольку OpenAI больше не предоставит ключ. Если вы потеряете его, вам нужно будет создать новый.
Заметка: Полный исходный код доступен по адресу Репозиторий GitHub.
Теперь, когда у вас есть ключ API, откройте IDE и импортируйте класс SKLLMConfig из библиотеки Scikit-LLM. Этот класс позволяет вам устанавливать параметры конфигурации, связанные с использованием больших языковых моделей.
from skllm.config import SKLLMConfig В этой категории требуется, чтобы вы установили ключ OpenAI API и сведения об организации.
# Set your OpenAI API key
SKLLMConfig.set_openai_key("Your API key")
# Set your OpenAI organization
SKLLMConfig.set_openai_org("Your organization ID") Идентификатор и название организации — это не одно и то же. Идентификатор организации — это уникальный идентификатор вашей организации. Чтобы получить идентификатор вашей организации, перейдите на страницу настроек. Фонд ОпенАИ И скопируйте его. Теперь вы установили связь между Scikit-LLM и большой языковой моделью.
Заметка: Scikit-LLM требует наличия плана с оплатой по мере использования. Это связано с тем, что бесплатная демо-учетная запись OpenAI имеет максимальную скорость ввода трех запросов в минуту, чего недостаточно для Scikit-LLM.
Попытка использовать бесплатную демо-учетную запись приведет к ошибке, аналогичной той, которая показана ниже при выполнении анализа текста. Проверять Каков лимит токена ChatGPT и можно ли его обойти?

Чтобы узнать больше об ограничениях скорости. Идти к Страница ограничения скорости OpenAI.
Заметка: Поставщик LLM не ограничивается только OpenAI. Вы также можете использовать других поставщиков LLM. Проверять Сравнение Claude и ChatGPT: какой LLM лучше всего подходит для повседневных задач?
Импортируйте необходимые библиотеки и загрузите набор данных.
Импортируйте функцию pandas, которую вы будете использовать для загрузки набора данных. Кроме того, из Scikit-LLM и scikit-learn импортируйте необходимые классы.
import pandas as pd
from skllm import ZeroShotGPTClassifier, MultiLabelZeroShotGPTClassifier
from skllm.preprocessing import GPTSummarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MultiLabelBinarizer Затем загрузите набор данных, для которого вы хотите выполнить текстовый анализ. Этот код использует набор данных фильмов IMDB. Однако вы можете изменить его, чтобы использовать предпочитаемый вами набор данных.
# Load your dataset
data = pd.read_csv("imdb_movies_dataset.csv")
# Extract the first 100 rows
data = data.head(100) Не обязательно использовать только первые 100 строк набора данных. Вы можете использовать весь набор данных.
Затем извлеките объекты и маркируйте столбцы. Затем разделите набор данных на наборы для обучения и тестирования.
# Extract relevant columns
X = data['Description']
# Assuming 'Genre' contains the labels for classification
y = data['Genre']
# Split the dataset into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) Столбец «Жанр» содержит рейтинги, которые вы хотите спрогнозировать.
Классификация текста без снимков с использованием Scikit-LLM
Классификация текста без снимков — это функция, предлагаемая большими языковыми моделями. Он классифицирует текст по заранее определенным категориям, не требуя явного обучения помеченным данным. Эта возможность очень полезна при работе с задачами, где вам нужно классифицировать текст по категориям, чего вы не ожидали при обучении модели.
Чтобы выполнить классификацию текста без снимков с помощью Scikit-LLM, используйте класс ZeroShotGPTClassifier.
# Perform Zero-Shot Text Classification
zero_shot_clf = ZeroShotGPTClassifier(openai_model="gpt-3.5-turbo")
zero_shot_clf.fit(X_train, y_train)
zero_shot_predictions = zero_shot_clf.predict(X_test)
# Print Zero-Shot Text Classification Report
print("Zero-Shot Text Classification Report:")
print(classification_report(y_test, zero_shot_predictions)) Результат будет следующим:
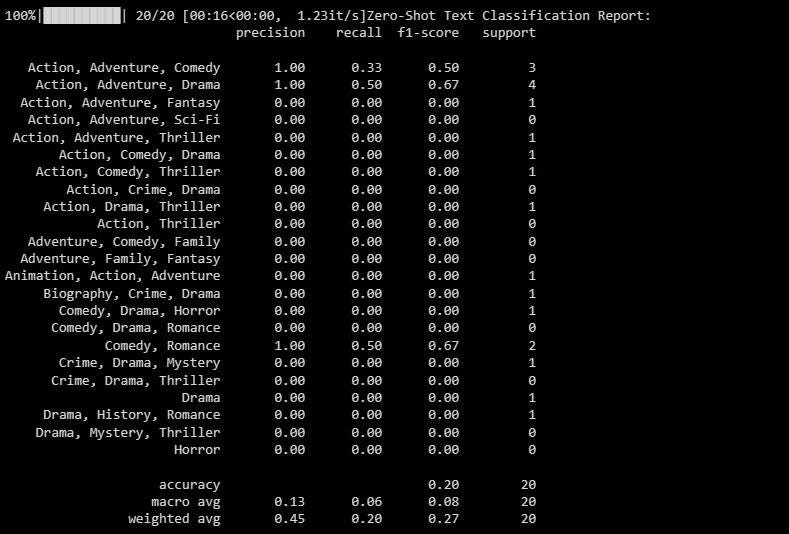
Отчет о классификации предоставляет метрики для каждой классификации, которую пытается предсказать модель.
Классификация текста по нескольким меткам без снимков с использованием Scikit-LLM
В некоторых сценариях один текст может принадлежать одновременно нескольким категориям. Традиционные модели классификации с трудом справляются со своей задачей. С другой стороны, Scikit-LLM делает эту классификацию возможной. Маркировка текста несколькими нулевыми метками имеет решающее значение для присвоения нескольких описательных меток одному образцу текста.
Используйте MultiLabelZeroShotGPTClassifier, чтобы предсказать соответствующие метки для каждого образца текста.
# Perform Multi-Label Zero-Shot Text Classification
# Make sure to provide a list of candidate labels
candidate_labels = ["Action", "Comedy", "Drama", "Horror", "Sci-Fi"]
multi_label_zero_shot_clf = MultiLabelZeroShotGPTClassifier(max_labels=2)
multi_label_zero_shot_clf.fit(X_train, candidate_labels)
multi_label_zero_shot_predictions = multi_label_zero_shot_clf.predict(X_test)
# Convert the labels to binary array format using MultiLabelBinarizer
mlb = MultiLabelBinarizer()
y_test_binary = mlb.fit_transform(y_test)
multi_label_zero_shot_predictions_binary = mlb.transform(multi_label_zero_shot_predictions)
# Print Multi-Label Zero-Shot Text Classification Report
print("Multi-Label Zero-Shot Text Classification Report:")
print(classification_report(y_test_binary, multi_label_zero_shot_predictions_binary)) В приведенном выше коде вы можете указать, к каким отфильтрованным меткам может принадлежать ваш текст.
Результат такой, как показано ниже:
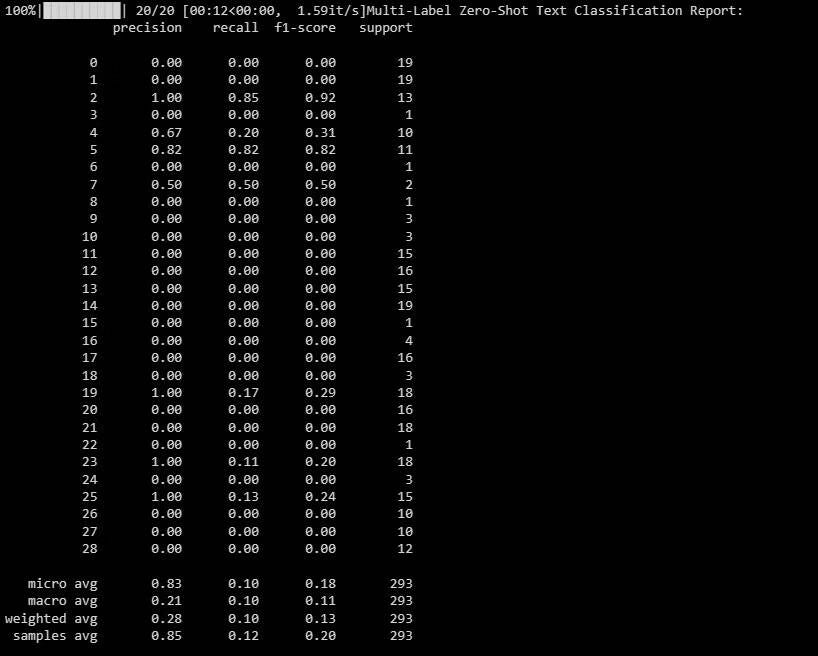
Этот отчет поможет вам понять, насколько хорошо ваша модель работает для каждой метки в классификации с несколькими метками.
Маршрутизация текста с использованием Scikit-LLM
При маршрутизации текста текстовые данные преобразуются в цифровой формат, понятный моделям машинного обучения. Для этой цели Scikit-LLM предоставляет функцию GPTectorizer. Позволяет конвертировать текст в векторы фиксированного размера с использованием моделей GPT.
Добиться этого можно, используя термин «частота» — обратная частота документов.
# Perform Text Vectorization using TF-IDF
tfidf_vectorizer = TfidfVectorizer(max_features=1000)
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
X_test_tfidf = tfidf_vectorizer.transform(X_test)
# Print the TF-IDF vectorized features for the first few samples
print("TF-IDF Vectorized Features (First 5 samples):")
print(X_train_tfidf[:5]) # Change to X_test_tfidf if you want to print the test set Вот результат:
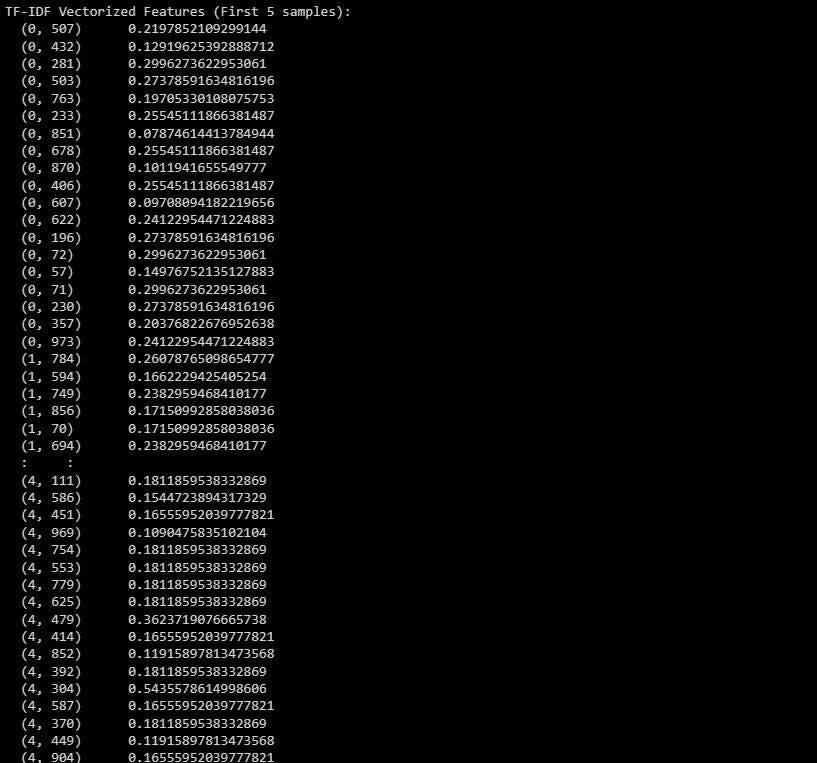
Выходные данные представляют собой векторизованные функции TF-IDF первых пяти выборок в наборе данных. Проверять Расширения Chrome на базе искусственного интеллекта для обобщения видео на YouTube.
Обобщение текста с использованием Scikit-LLM
Краткое изложение текста помогает сократить его часть, сохраняя при этом наиболее важную информацию. Scikit-LLM предоставляет функцию GPTSummarizer, которая использует шаблоны GPT для создания кратких сводок текста.
# Perform Text Summarization
summarizer = GPTSummarizer(openai_model="gpt-3.5-turbo", max_words=15)
summaries = summarizer.fit_transform(X_test)
print(summaries) Вывод следующий:
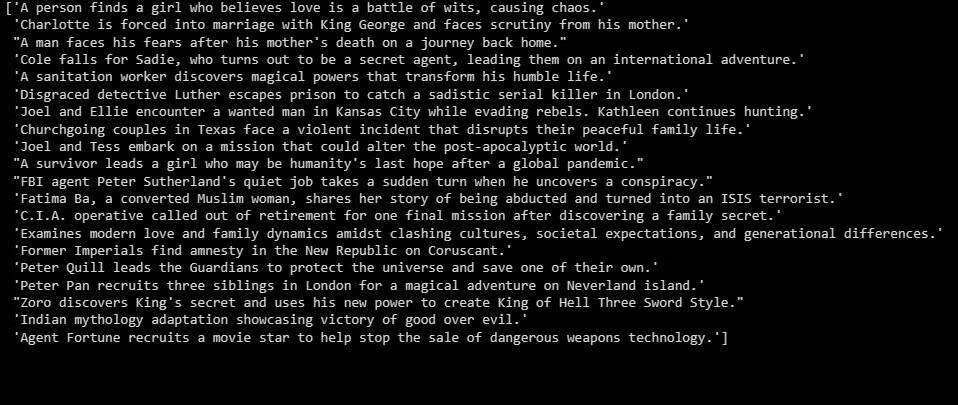
Выше приведено краткое изложение выявленных данных.
Общие вопросы
Вопрос 1. Что такое Scikit-LLM и что это значит для больших языковых моделей?
Scikit-LLM — это программная библиотека, используемая для анализа текстов с использованием больших языковых моделей (LLM), которые представляют собой модели, обученные на больших наборах лингвистических данных. Эти модели позволяют нам понимать язык и различные возможные значения слов, предложений и текстов.
В2. Каковы виды использования Scikit-LLM?
Scikit-LLM можно использовать во многих приложениях, таких как классификация текстов по различным категориям, извлечение ключевых слов из текстов, обнаружение лингвистических связей между словами и синтез новых текстов на основе существующих текстов.
Вопрос 3. Должен ли я быть опытным программистом, чтобы использовать Scikit-LLM?
Не обязательно. Любой, кто интересуется анализом текста, может легко научиться использовать Scikit-LLM. Однако любой опыт программирования и понимание основ естественного языка будут полезны.
Вопрос 4. Нужно ли использовать большие данные для обучения моделей Scikit-LLM?
Да, обучение моделей Scikit-LLM обычно требует использования больших наборов данных. Но для анализа текстов можно использовать уже готовые модели, предварительно обученные людьми и организациями.
Вопрос 5. На каких языках можно обучать модели Scikit-LLM?
Модели Scikit-LLM можно обучать на разных языках, включая английский, испанский, китайский, арабский и другие. Есть готовые шаблоны для многих популярных языков. Проверять Как создать собственный экземпляр ChatGPT с вашими личными данными.
Создание приложений на основе моделей LLM
Scikit-LLM открывает мир возможностей для анализа текста с использованием больших лингвистических моделей. Понимание технологии, лежащей в основе больших языковых моделей, имеет решающее значение. Это поможет вам понять его сильные и слабые стороны, что поможет вам создавать эффективные приложения на основе этой передовой технологии. Теперь вы можете просмотреть Улучшите работу с ChatGPT, создав собственные профили пользователей..