We zijn onlangs getuige geweest van een versnelde ontwikkeling op het gebied van kunstmatige intelligentie, omdat we nu een groter vermogen hebben om gegevens te analyseren en te begrijpen op manieren die voorheen niet mogelijk waren. Deze ontwikkeling roept echter belangrijke vragen op met betrekking tot privacy en gegevensbeveiliging, vooral als het gaat om persoonlijke gegevens op sociale-mediasites.
Een van de nieuwste manieren waarop socialemediabedrijven inkomsten genereren met gebruikersgegevens is via deals met bedrijven op het gebied van kunstmatige intelligentie. Maar kunnen gewone gebruikers iets doen om hun gegevens en inhoud te beschermen?
In dit artikel analyseren we de impact van kunstmatige intelligentie op de veiligheid van uw sociale accounts en bespreken we wat u kunt doen om uw privacy te beschermen. We zullen de potentiële problemen en uitdagingen bekijken waarmee persoonlijke gegevens op sociale-mediaplatforms worden geconfronteerd en advies geven over hoe we effectief met deze gevolgen kunnen omgaan. Verifiëren Kunstmatige intelligentie en privacyrisico's: uw gegevens beschermen in een geautomatiseerde wereld.

Sociale mediaplatforms sluiten deals met bedrijven op het gebied van kunstmatige intelligentie
Het gebruik van gegevens uit sociale media om generatieve AI-modellen te trainen is een controversiële stap geweest, maar dat lijkt sociale-mediabedrijven er niet van te weerhouden gebruikersgegevens uit te delen in ruil voor meer geld.
Meta gebruikt zijn sociale netwerkgegevens al om generatieve AI-modellen te trainen, wat in 2023 zal worden aangekondigd op Meta Connect. Dit omvat Meta AI en functies zoals Maak posters met kunstmatige intelligentie op WhatsApp.
Zoals Mike Clark, directeur productmanagement van Meta, verklaarde in een bericht op... Meta-redactiekamer:
“Openbaar gedeelde berichten van Instagram en Facebook – inclusief afbeeldingen en tekst – maakten deel uit van de gegevens die werden gebruikt om de generatieve AI-modellen te trainen die ten grondslag liggen aan de functies die we op Connect hebben aangekondigd.”
Deze trend lijkt in 2024 niet te vertragen. Volgens... Aan ReutersReddit heeft een overeenkomst bereikt met Google om de inhoud van het sociale mediaplatform beschikbaar te maken voor het trainen van kunstmatige intelligentiemodellen.
Bevestig de indiening Reddit S-1 Voor de beursintroductie, die op 22 februari 2024 werd ingediend, onderzoekt het bedrijf licentieovereenkomsten. In de inzending staat:
“Reddit-gegevens zijn een belangrijk onderdeel van het bouwen van de huidige AI-technologie en veel LLM-modellen. “Wij geloven dat de enorme verzameling conversatiegegevens en kennis van Reddit een rol zal blijven spelen bij het trainen en verbeteren van LLM-modellen.”
Het specificeert dat Reddit zich “in de beginfase bevindt van het toestaan van derden om toegang te verlenen tot onderzoek, analyse en weergave van historische en realtime gegevens van ons platform” voor het trainen van LLM’s.
Hoewel Meta en Reddit twee van de grootste namen op sociale media zijn, zijn ze niet de enige platforms die betrokken zijn bij het gebruik van sociale mediagegevens om kunstmatige intelligentie te trainen. Volgens een rapport uitgegeven door 404 MediaTumblr en WordPress.com bereiden zich voor om gebruikersgegevens te verkopen aan Midjourney en OpenAI.
Kunt u voorkomen dat sociale platforms uw accountgegevens verkopen om kunstmatige intelligentie te trainen?
De kans is groot dat als u Facebook, Instagram, Reddit, Tumblr of WordPress.com gebruikt, uw openbaar beschikbare inhoud al is gebruikt om uw LLM-model te trainen.
Als u bijvoorbeeld de zoekfunctie gebruikt voor Washington Post Om te zien welke websites zijn opgenomen in de Google C4-dataset, die is gebruikt als onderdeel van een trainingsoefening Gemini, zul je zien dat Reddit.com 7.9 miljoen tokens vertegenwoordigt.
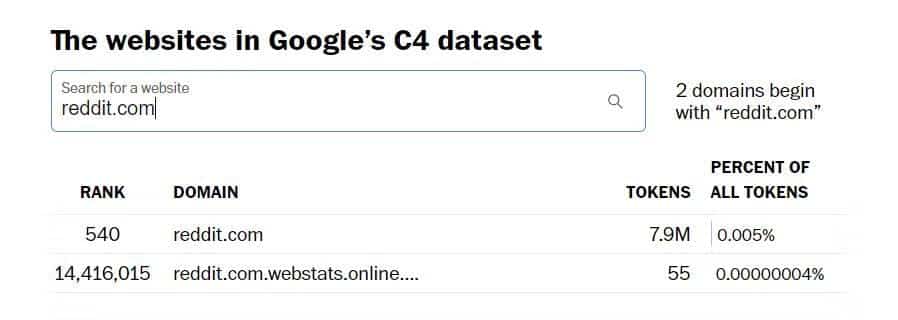
Tumblr.com heeft meer dan 1.6 miljoen pictogrammen. Mijn kleine website, die WordPress.com gebruikt, heeft 14000 tokens, dus kleine persoonlijke blogs zijn waarschijnlijk in de dataset opgenomen.
En met de voortdurende deals tussen AI-bedrijven en sociale-mediabedrijven zullen licentieovereenkomsten betekenen dat deze gegevens actief worden verkocht in plaats van simpelweg van het internet te worden verwijderd.
Maar als het om toekomstige verwerking gaat, wat kunt u dan doen aan de beveiliging van uw gegevens? Meta heeft hiervoor een model geleverd Rechten van betrokkenen op het gebied van generatieve AI Waarmee u bezwaar kunt maken of de verwerking van uw persoonsgegevens door derden kunt beperken om de generatieve AI-modellen van Meta te trainen.
Op dit formulier kunt u verzoeken indienen met betrekking tot uw persoonlijke gegevens van derden die worden gebruikt om de generatieve AI-modellen van Meta te trainen. Over het algemeen zijn persoonlijke gegevens gegevens over u. Voorbeelden hiervan zijn uw naam, huisadres, telefoonnummer of e-mailadres. Informatie van derden omvat informatie die publiekelijk beschikbaar is op internet en gelicentieerde informatie die eigendom is van iemand anders en waarvoor Meta toestemming heeft gegeven om deze te gebruiken.
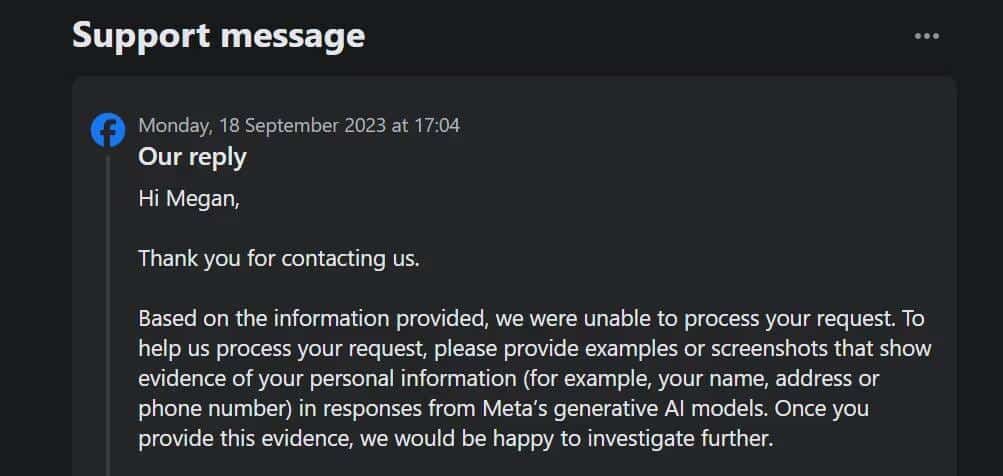
Het is vermeldenswaard dat u met deze optie geen bezwaar kunt maken tegen de verwerking van uw gegevens door Meta om zijn generatieve AI te trainen. Bovendien, toen ik via het formulier een ticket indiende om bezwaar te maken tegen het gebruik van mijn persoonlijke gegevens, vroeg het supportticket mij om te bewijzen dat mijn persoonlijke gegevens inderdaad in de generatieve AI-resultaten van Meta verschenen.
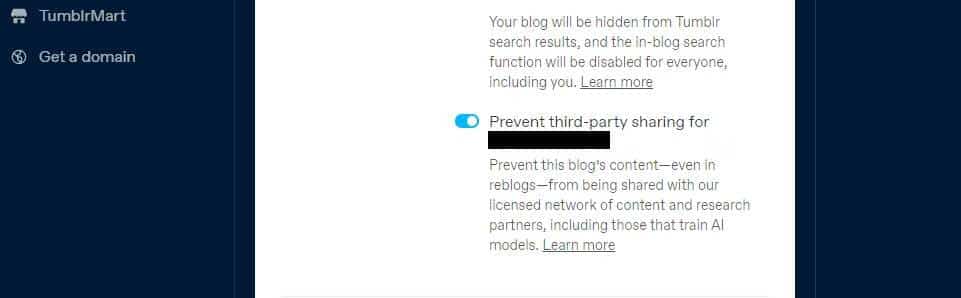
Tumblr heeft ook een optie geïntroduceerd waarmee u zich kunt afmelden voor het delen van uw openbare bloginhoud met derden via uw bloginstellingen. Je kunt het vinden in je instellingen door op je blog te klikken en naar beneden te scrollen Zichtbaarheidsinstellingen. kies dan Voorkom dat derden uw blog delen.
Als het om een platform als Instagram gaat, kun je proberen je account om te zetten Instagram naar privé Om het gebruik van uw gegevens te voorkomen. Dit garandeert niet dat uw gegevens niet zullen worden gebruikt, maar aangezien datamining voor LLM gericht lijkt te zijn op openbare gegevens, kan dit een potentiële garantie zijn.
U kunt uw X (Twitter)-account ook privé maken, maar ook dit is slechts een mogelijke voorzorgsmaatregel en garandeert niet dat uw gegevens privé blijven.
Hij stelde voor Gezamenlijke verklaring Veel nationale informatiecommissarissen en experts over de hele wereld hebben een aantal maatregelen uitgevaardigd voor individuen die de privacyrisico's willen verminderen die worden veroorzaakt door het verzamelen van gegevens door AI-bedrijven. Advies omvat:
- Lees de voorwaarden en het privacybeleid van de website om te zien hoe uw persoonlijke gegevens worden gedeeld.
- Beperk de informatie die u online plaatst, vooral gevoelige informatie.
- U moet uw privacy-instellingen beheren.
- Denk op de lange termijn na over de informatie die u online deelt.
- Neem contact op met het socialemediabedrijf of de website als u denkt dat uw gegevens ten onrechte zijn gedeeld. Als u niet tevreden bent met hun antwoord, dient u een klacht in bij de relevante gegevensbeschermingsautoriteit.
Jij kan ook Verwijder wat informatie online Als u zich niet op uw gemak voelt als derden er toegang toe hebben, ook al is de openbaar beschikbare informatie in uw persoonlijke accounts mogelijk al gekopieerd.
Helaas kunnen wij als gewone gebruikers niet veel doen om onze gegevens te beschermen tegen AI-bedrijven. Echte controle over deze informatie zal waarschijnlijk alleen mogelijk zijn met de hulp van toezichthouders. Je kunt nu bekijken Zijn menselijke capaciteiten of kunstmatige intelligentie superieur in het detecteren van deep-fake-technologie?.