L’analyse des données et des textes est devenue essentielle pour comprendre le contexte et extraire des informations précieuses des différentes informations disponibles. L'un des outils d'analyse avancés qui suscite l'intérêt de nombreux chercheurs et analystes est Scikit-LLM. Cet outil permet l'analyse de texte à l'aide de grands modèles linguistiques, ce qui facilite l'extraction efficace de modèles et d'informations importants à partir de textes.
Scikit-LLM est un package Python qui permet d'intégrer des modèles de langage étendus (LLM) dans le framework Scikit-Learn. Ce qui aide à accomplir les tâches d’analyse de texte. Si vous connaissez Scikit-Learn, il vous sera plus facile de travailler avec Scikit-LLM.
Il est important de noter que Scikit-LLM ne remplace pas Scikit-Learn. Alors que Scikit-Learn est une bibliothèque d'apprentissage automatique à usage général, Scikit-LLM est spécifiquement conçue pour les tâches d'analyse de texte.
Dans cet article, nous explorerons comment utiliser Scikit-LLM pour l'analyse de texte et comment cet outil peut vous aider à comprendre le contenu du texte de manière avancée. Vérifier Les meilleures bibliothèques d'apprentissage automatique pour acquérir une expérience supplémentaire.

Premiers pas avec Scikit-LLM
Pour commencer à utiliser Scikit-LLM, vous devrez installer la bibliothèque et configurer votre clé API. Pour installer la bibliothèque, ouvrez votre IDE préféré et créez un nouvel environnement virtuel. Cela aidera à éviter tout conflit potentiel de version de bibliothèque. Exécutez ensuite la commande suivante dans Terminal.
pip install scikit-llm Cette commande installera Scikit-LLM et ses dépendances requises.
Pour configurer votre propre clé API, vous devez l'obtenir auprès du fournisseur LLM sur lequel vous souhaitez compter. Pour obtenir la clé API OpenAI, procédez comme suit :
Aller à Page API OpenAI. Cliquez ensuite sur votre profil situé dans le coin supérieur de la fenêtre. Localiser Afficher les clés API. Cela vous mènera à la page Clés API.
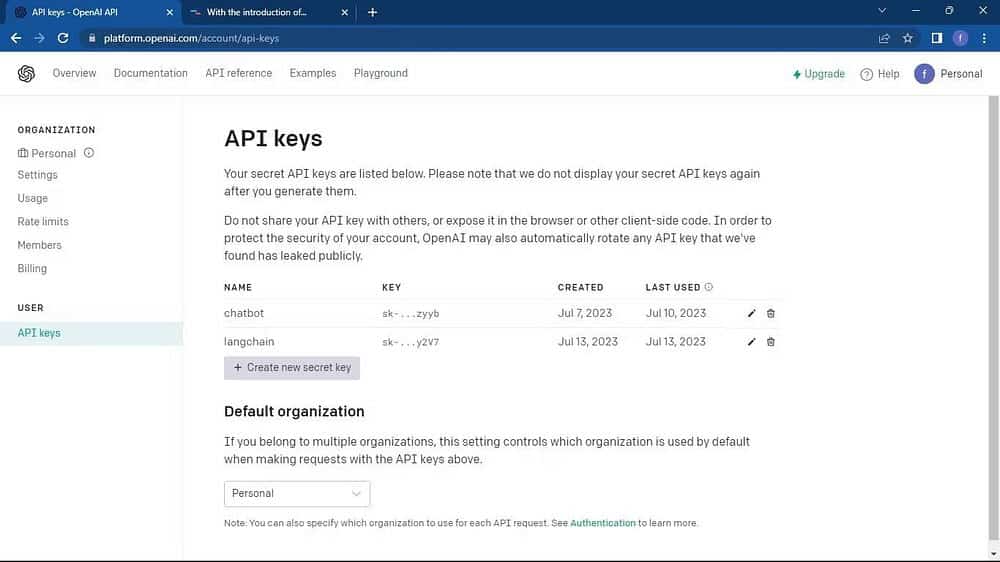
Sur la page Clés API, cliquez sur le bouton Créer une nouvelle clé secrète.
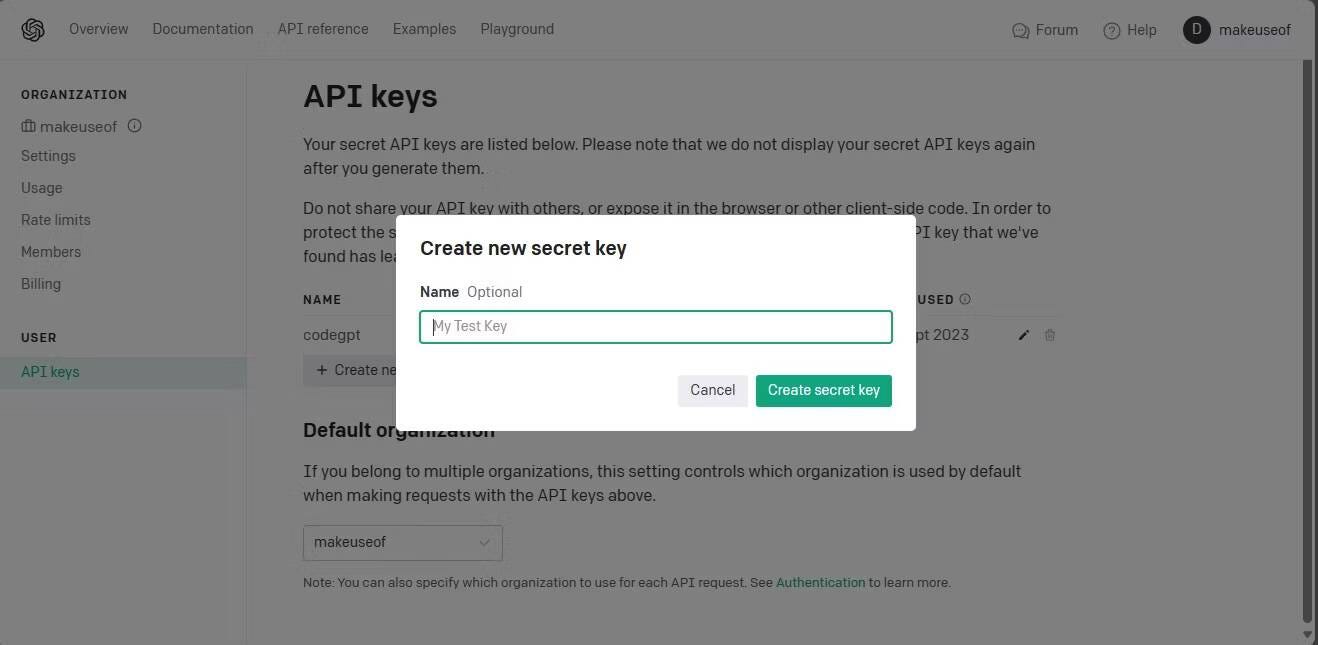
Nommez votre clé API et cliquez sur le bouton « Générer la clé secrète » pour générer la clé. Après la génération, vous devrez copier la clé et la stocker dans un endroit sûr car OpenAI n'exposera plus la clé. Si vous le perdez, vous devrez en créer un nouveau.
Note: Le code source complet est disponible sur Référentiel GitHub.
Maintenant que vous disposez de la clé API, ouvrez l'IDE et importez la classe SKLLMConfig depuis la bibliothèque Scikit-LLM. Cette classe vous permet de définir des options de configuration liées à l'utilisation de grands modèles de langage.
from skllm.config import SKLLMConfig Cette catégorie attend de vous que vous définissiez votre clé API OpenAI et les détails de votre organisation.
# Set your OpenAI API key
SKLLMConfig.set_openai_key("Your API key")
# Set your OpenAI organization
SKLLMConfig.set_openai_org("Your organization ID") L’ID et le nom de l’organisation ne sont pas la même chose. L'ID d'organisation est un identifiant unique pour votre organisation. Pour obtenir l'ID de votre organisation, accédez à la page Paramètres Fondation OpenAI Et copiez-le. Vous avez maintenant établi une connexion entre Scikit-LLM et le grand modèle de langage.
Note: Scikit-LLM nécessite que vous disposiez d'un plan de paiement à l'utilisation. En effet, le compte démo gratuit OpenAI a un taux d'entrée maximum de trois requêtes par minute, ce qui n'est pas suffisant pour Scikit-LLM.
Essayer d'utiliser le compte démo gratuit entraînera une erreur similaire à celle illustrée ci-dessous lors de l'analyse de texte. Vérifier Quelle est la limite de jetons ChatGPT et pouvez-vous la contourner ?

Pour en savoir plus sur les limites de taux. Aller à Page des limites de débit OpenAI.
Note: Le fournisseur LLM ne se limite pas à OpenAI. Vous pouvez également utiliser d'autres fournisseurs LLM. Vérifier Comparaison Claude vs ChatGPT : Quel LLM est le meilleur pour les tâches quotidiennes ?
Importez les bibliothèques requises et chargez l'ensemble de données
Importez la fonction pandas que vous utiliserez pour charger l'ensemble de données. De plus, depuis Scikit-LLM et scikit-learn, importez les classes requises.
import pandas as pd
from skllm import ZeroShotGPTClassifier, MultiLabelZeroShotGPTClassifier
from skllm.preprocessing import GPTSummarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MultiLabelBinarizer Ensuite, téléchargez l'ensemble de données sur lequel vous souhaitez effectuer une analyse de texte. Ce code utilise l'ensemble de données de film IMDB. Cependant, vous pouvez le modifier pour utiliser l'ensemble de données que vous préférez.
# Load your dataset
data = pd.read_csv("imdb_movies_dataset.csv")
# Extract the first 100 rows
data = data.head(100) Il n'est pas obligatoire d'utiliser uniquement les 100 premières lignes de l'ensemble de données. Vous pouvez utiliser l'intégralité de l'ensemble de données.
Ensuite, extrayez les colonnes de fonctionnalités et d’étiquettes. Divisez ensuite votre ensemble de données en ensembles de formation et de test.
# Extract relevant columns
X = data['Description']
# Assuming 'Genre' contains the labels for classification
y = data['Genre']
# Split the dataset into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) La colonne Genre contient les notes que vous souhaitez prévoir.
Classification de texte sans instantané à l'aide de Scikit-LLM
La classification de texte sans instantané est une fonctionnalité offerte par les grands modèles de langage. Il classe le texte dans des catégories prédéfinies sans nécessiter de formation explicite sur les données étiquetées. Cette fonctionnalité est très utile lorsque vous traitez des tâches dans lesquelles vous devez classer du texte dans des catégories auxquelles vous ne vous attendiez pas lors de la formation du modèle.
Pour effectuer une classification de texte sans instantanés à l'aide de Scikit-LLM, utilisez la classe ZeroShotGPTClassifier.
# Perform Zero-Shot Text Classification
zero_shot_clf = ZeroShotGPTClassifier(openai_model="gpt-3.5-turbo")
zero_shot_clf.fit(X_train, y_train)
zero_shot_predictions = zero_shot_clf.predict(X_test)
# Print Zero-Shot Text Classification Report
print("Zero-Shot Text Classification Report:")
print(classification_report(y_test, zero_shot_predictions)) Le résultat sera le suivant :
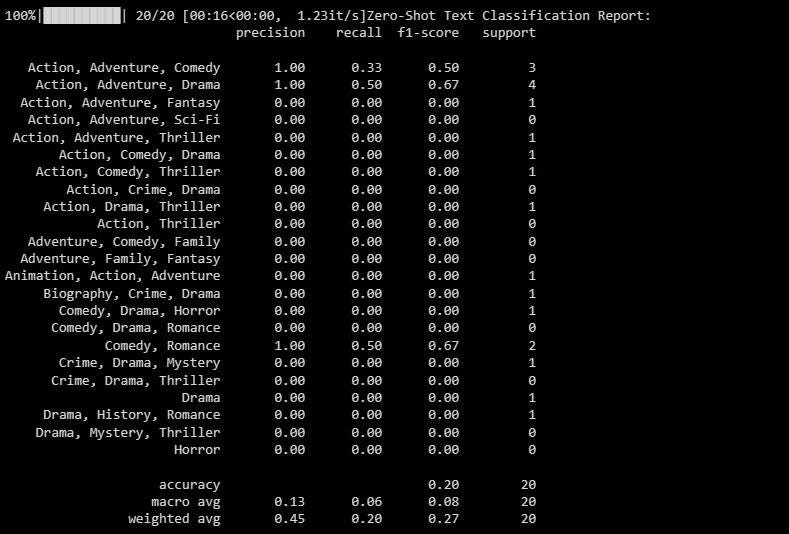
Le rapport de classification fournit des mesures pour chaque classification que le modèle tente de prédire.
Classification de texte multi-étiquettes sans instantanés à l'aide de Scikit-LLM
Dans certains scénarios, un seul texte peut appartenir à plusieurs catégories à la fois. Les modèles de classification traditionnels peinent à faire leur travail. En revanche, Scikit-LLM rend cette classification possible. L'étiquetage du texte avec plusieurs étiquettes zéro est crucial pour attribuer plusieurs étiquettes descriptives à un seul échantillon de texte.
Utilisez MultiLabelZeroShotGPTClassifier pour prédire les étiquettes appropriées pour chaque échantillon de texte.
# Perform Multi-Label Zero-Shot Text Classification
# Make sure to provide a list of candidate labels
candidate_labels = ["Action", "Comedy", "Drama", "Horror", "Sci-Fi"]
multi_label_zero_shot_clf = MultiLabelZeroShotGPTClassifier(max_labels=2)
multi_label_zero_shot_clf.fit(X_train, candidate_labels)
multi_label_zero_shot_predictions = multi_label_zero_shot_clf.predict(X_test)
# Convert the labels to binary array format using MultiLabelBinarizer
mlb = MultiLabelBinarizer()
y_test_binary = mlb.fit_transform(y_test)
multi_label_zero_shot_predictions_binary = mlb.transform(multi_label_zero_shot_predictions)
# Print Multi-Label Zero-Shot Text Classification Report
print("Multi-Label Zero-Shot Text Classification Report:")
print(classification_report(y_test_binary, multi_label_zero_shot_predictions_binary)) Dans le code ci-dessus, vous pouvez spécifier à quelles étiquettes filtrées votre texte peut appartenir.
Le résultat est le suivant :
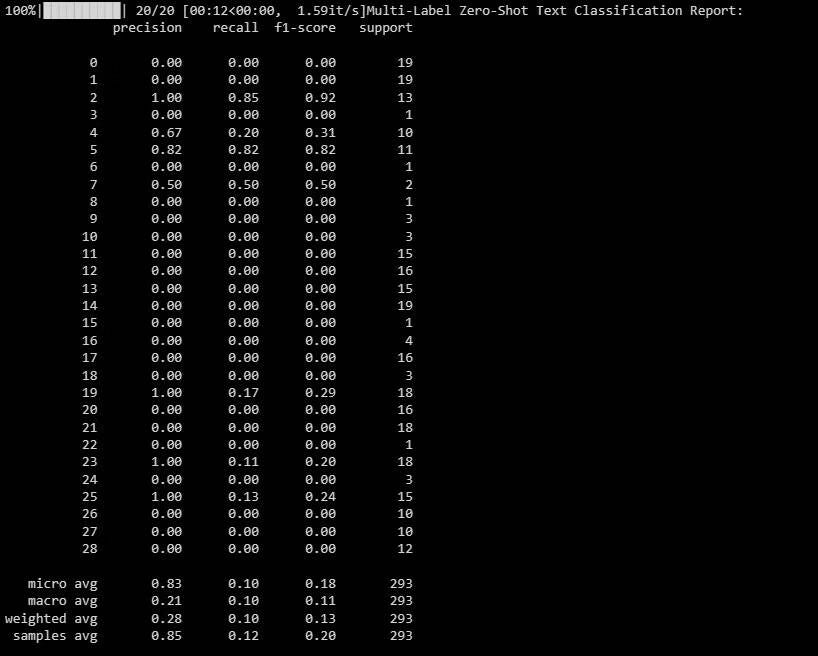
Ce rapport vous aide à comprendre les performances de votre modèle pour chaque étiquette dans la classification multi-étiquettes.
Routage de texte à l'aide de Scikit-LLM
Lors du routage de texte, les données textuelles sont converties dans un format numérique que les modèles d'apprentissage automatique peuvent comprendre. Scikit-LLM fournit une fonction GPTectorizer à cet effet. Vous permet de convertir du texte en vecteurs de dimension fixe à l'aide de modèles GPT.
Vous pouvez y parvenir en utilisant la fréquence des termes – fréquence inverse des documents.
# Perform Text Vectorization using TF-IDF
tfidf_vectorizer = TfidfVectorizer(max_features=1000)
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
X_test_tfidf = tfidf_vectorizer.transform(X_test)
# Print the TF-IDF vectorized features for the first few samples
print("TF-IDF Vectorized Features (First 5 samples):")
print(X_train_tfidf[:5]) # Change to X_test_tfidf if you want to print the test set Voici le résultat :
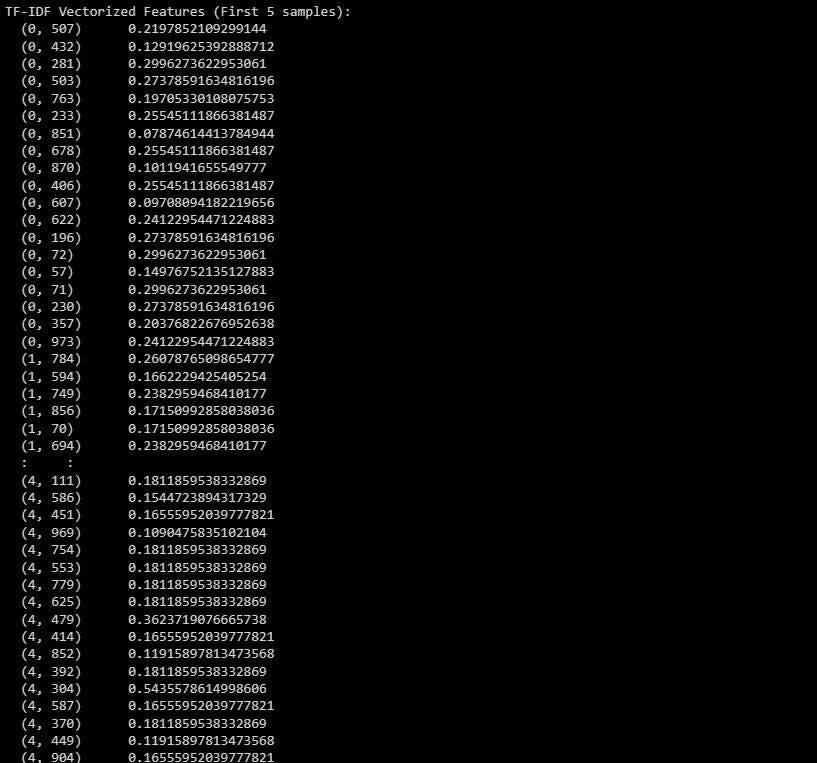
La sortie représente les caractéristiques TF-IDF vectorisées des cinq premiers échantillons de l’ensemble de données. Vérifier Extensions Chrome optimisées par l'intelligence artificielle pour résumer les vidéos YouTube.
Résumé de texte à l'aide de Scikit-LLM
Résumer un texte permet de condenser une partie du texte tout en conservant ses informations les plus importantes. Scikit-LLM fournit la fonction GPTSummarizer, qui utilise des modèles GPT pour créer des résumés concis de texte.
# Perform Text Summarization
summarizer = GPTSummarizer(openai_model="gpt-3.5-turbo", max_words=15)
summaries = summarizer.fit_transform(X_test)
print(summaries) Le résultat est le suivant :
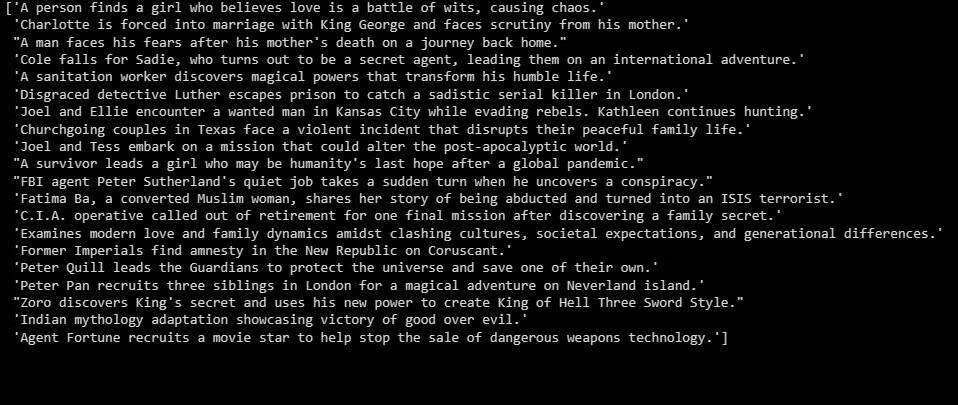
Ce qui précède est un résumé des données identifiées.
Foire Aux Questions
T1. Qu'est-ce que Scikit-LLM et qu'est-ce que cela signifie pour les grands modèles de langage ?
Scikit-LLM est une bibliothèque logicielle utilisée pour analyser des textes à l'aide de grands modèles linguistiques (LLM), qui sont des modèles formés sur de grands ensembles de données linguistiques. Ces modèles permettent de comprendre le langage et les différents sens possibles des mots, des phrases et des textes.
Q2. Quelles sont les utilisations de Scikit-LLM ?
Scikit-LLM peut être utilisé dans de nombreuses applications, telles que la classification de textes en différentes catégories, l'extraction de mots-clés de textes, la découverte de relations linguistiques entre des mots et la synthèse de nouveaux textes basés sur des textes existants.
Q3. Dois-je être un programmeur expérimenté pour utiliser Scikit-LLM ?
Pas nécessairement. Toute personne intéressée par l'analyse de texte peut facilement apprendre à utiliser Scikit-LLM. Cependant, toute expérience en programmation et compréhension des bases du langage naturel sera bénéfique.
Q4. Dois-je utiliser le Big Data pour entraîner les modèles Scikit-LLM ?
Oui, la formation des modèles Scikit-LLM nécessite généralement l'utilisation de grands ensembles de données. Mais des modèles prêts à l’emploi, pré-entraînés par des personnes et des organisations, peuvent être utilisés pour analyser des textes.
Q5. Dans quels langages les modèles Scikit-LLM peuvent-ils être formés ?
Les modèles Scikit-LLM peuvent être formés dans de nombreuses langues différentes, notamment l'anglais, l'espagnol, le chinois, l'arabe et d'autres. Il existe des modèles prêts à l'emploi pour de nombreuses langues populaires. Vérifier Comment créer une instance ChatGPT personnalisée avec vos données privées.
Création d'applications basées sur des modèles LLM
Scikit-LLM ouvre un monde de possibilités pour l'analyse de texte à l'aide de grands modèles linguistiques. Comprendre la technologie derrière les grands modèles de langage est crucial. Cela vous aidera à comprendre ses forces et ses faiblesses, ce qui pourra vous aider à créer des applications efficaces au-dessus de cette technologie de pointe. Vous pouvez voir maintenant Améliorez votre expérience ChatGPT en créant des personnalités d'utilisateur personnalisées.