Preparar Archivo robots.txt . Uno de los archivos más simples en un sitio web, pero también uno que puede causar mucho caos. Una sola letra fuera de lugar puede hacer mucho problemas de seo Tiene y evitará que los motores de búsqueda accedan a contenido importante en su sitio.
¿Alguna vez has oído hablar del término Robots.txt y te has preguntado cómo usarlo en un sitio web? La mayoría de los sitios web tienen un archivo Robots.txt personalizado, pero eso no significa que la mayoría webmasters Ellos entienden cómo lidiar con eso.
En este hilo, esperamos cambiar eso brindando una guía detallada sobre el archivo Robots.txt, así como también cómo puede controlar y limitar el acceso del motor de búsqueda a su sitio web.

Al final de este artículo, podrá responder preguntas como:
- ¿Qué es un archivo Robots.txt?
- ¿Cómo ayuda un archivo Robots.txt a mi sitio web?
- ¿Cómo agrego Robots.txt a WordPress?
- ¿Qué tipos de reglas puedo poner en Robots.txt?
- ¿Cómo puedo probar un archivo robots.txt?
- ¿Cómo implementan los sitios grandes de WordPress un archivo Robots.txt?
Hay muchos detalles que cubrir, ¡así que comencemos!
¿Qué es un archivo Robots.txt?
Antes de hablar sobre el archivo Robots.txt en sí, es importante definir qué significa Robots en este caso. Los robots son cualquier tipo derastreadoresque visita sitios web. El ejemplo más común son los rastreadores de motores de búsqueda. Este mecanismo rastrea la web para ayudar a los motores de búsqueda como Google a indexar y clasificar miles de millones de páginas en Internet.
Entonces, los bots, en general, son algo bueno para Internet... o al menos algo necesario. Pero eso no significa necesariamente que usted o cualquiera de los otros webmasters quieran que estos bots funcionen sin ningún tipo de restricción.
El deseo de controlar cómo interactúan los rastreadores web con los sitios web llevó a la creación del estándar de exclusión de bots a mediados de la década de XNUMX. El archivo Robots.txt es la opción práctica para este estándar: le permite controlar cómo los bots participantes interactúan con su sitio. Puede bloquear el rastreador por completo, limitar su acceso a ciertas áreas de su sitio y más.
Sin embargo, la parte de "participación" es importante. Un archivo robots.txt no puede obligar a un bot a seguir sus instrucciones. Y los bots maliciosos pueden ignorar el archivo robots.txt. Además, las organizaciones acreditadas ignoran algunos de los comandos que podrían agregar al archivo Robots.txt. Por ejemplo, Google ignorará cualquier regla que agregue a su archivo robots.txt sobre Con qué frecuencia visitado por robots rastreadores. Si enfrenta muchos problemas con los bots, una solución de seguridad podría ser como Cloudflare O Sucuri útil.
¿Por qué debería preocuparse por su archivo robots.txt?
Para la mayoría webmasters Las ventajas de un archivo robots.txt bien organizado se dividen en dos categorías:
- Optimice los recursos de rastreo para los motores de búsqueda diciéndoles que no pierdan el tiempo en las páginas que no desea que se indexen. Esto ayuda a garantizar que los motores de búsqueda se concentren en rastrear las páginas que más le interesan.
- Optimice el uso de su servidor bloqueando los bots que desperdician recursos.
El archivo Robots.txt no se trata de controlar qué páginas indexan los motores de búsqueda
El archivo Robots.txt no es una forma infalible de controlar qué páginas indexan los motores de búsqueda. Si su objetivo principal es evitar que ciertas páginas se incluyan en los resultados del motor de búsqueda, el enfoque correcto es utilizar metaelemento sin índice U otro método directo similar.
Esto se debe a que su archivo Robots.txt no les dice directamente a los motores de búsqueda que no indexen el contenido, solo les pide que no lo rastreen. Si bien Google no rastreará las áreas marcadas como no rastreadas dentro de su sitio, Google mismo Establece que Si un sitio externo se vincula a una página que excluye a través de su archivo Robots.txt, Google aún puede indexar esa página.
Las directivas de Robots.txt pueden no ser compatibles con todos los motores de búsqueda
Las instrucciones en los archivos robots.txt no pueden imponer un comportamiento específico en el sitio web por parte del rastreador porque es el rastreador el que decide si seguir o no estas instrucciones. Si bien Googlebot y otros rastreadores web respetables siguen las pautas de robots.txt, es posible que otros rastreadores no lo hagan. Entonces, si desea mantener la información a salvo de los rastreadores web, es mejor usar otros métodos de bloqueo, como proteger con contraseña los archivos privados en el servidor.
Cómo crear y editar un archivo Robots.txt
De forma predeterminada, WordPress crea automáticamente un archivo robots.txt predeterminado para su sitio. Entonces, incluso si no hace nada, su sitio ya debería tener el archivo robots.txt predeterminado. Puede probar si este es el caso agregando "/robots.txtal final de su nombre de dominio. Por ejemplo, muestra “https://www.dz-techs.com/robots.txtEl archivo robots.txt que usamos aquí en Dz Techs:
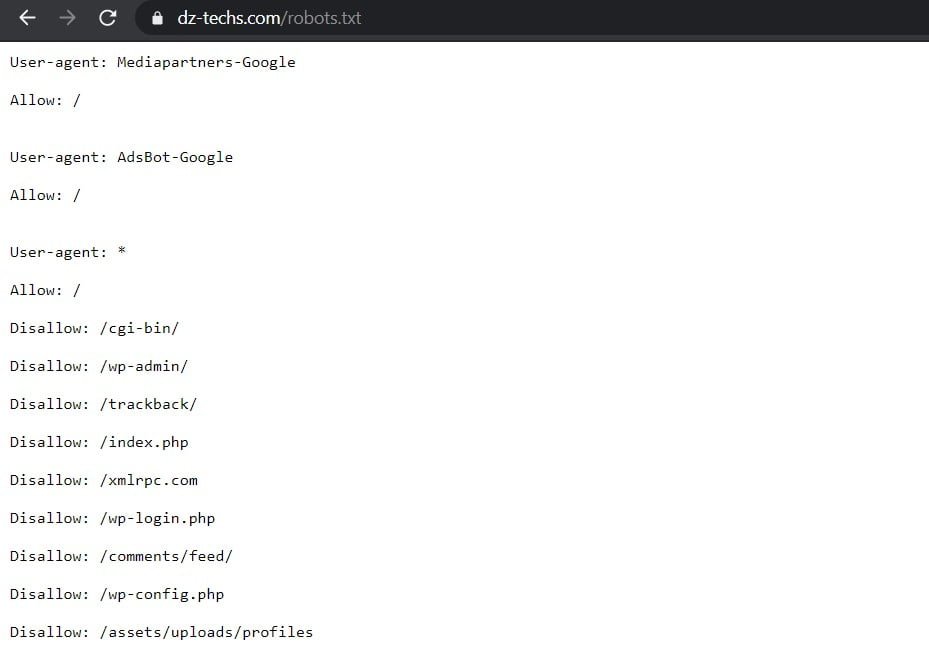
Como el archivo es predeterminado, no puede modificarlo directamente. Si desea modificar su archivo robots.txt, deberá crear un archivo personalizado en su servidor que pueda modificar según sea necesario. Aquí hay tres formas simples de hacerlo...
Cómo crear y editar un archivo Robots.txt con Yoast SEO
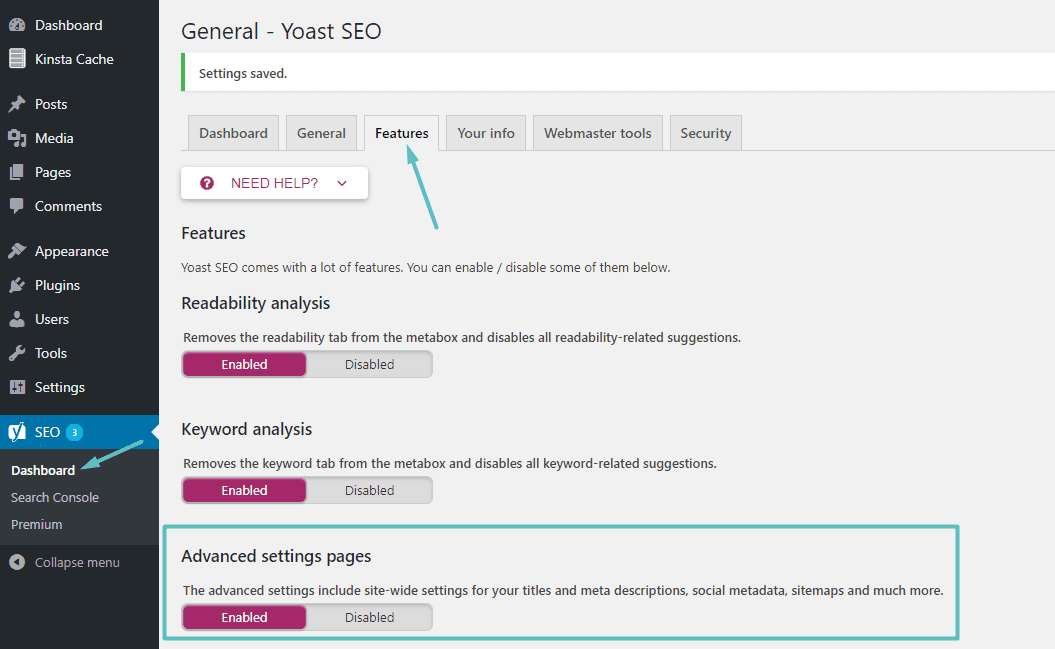
Si esta usando La famosa adición Yoast SEO, puede crear (y editar más tarde) un archivo robots.txt directamente desde la interfaz de Yoast. Antes de poder acceder a esta opción, debe habilitar Funciones avanzadas de Yoast SEO Yendo a SEO → Tablero → Características y habilite el control deslizante junto a Páginas de configuración avanzada:
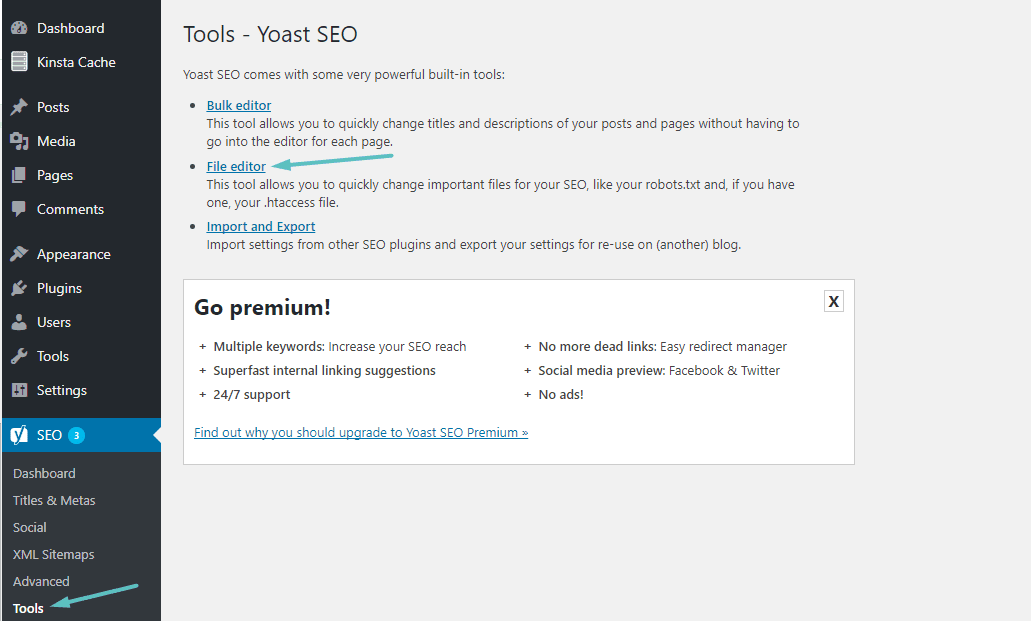
Una vez que lo habilites, puedes navegar a SEO → Herramientas y haciendo clic en Editor de archivos:
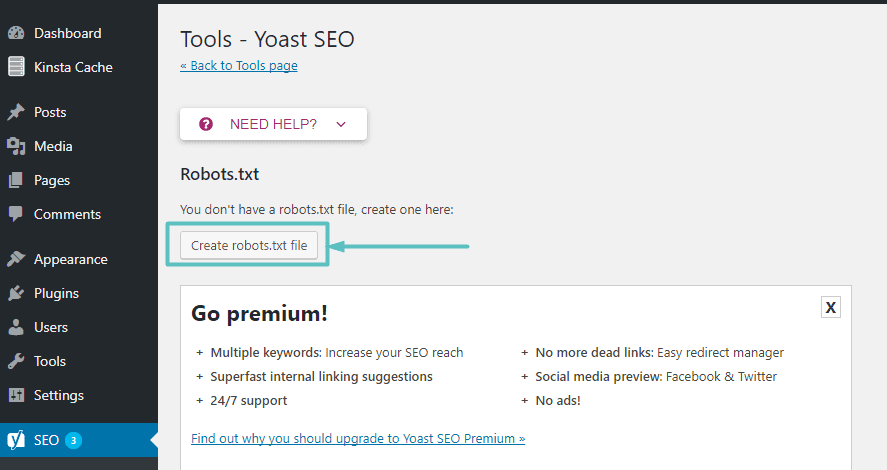
Asumiendo que el sitio web en realidad no tiene un archivo Robots.txt, Yoast le dará una opción Crear un archivo robots.txt:
Una vez que haga clic en este botón, podrá editar el contenido del archivo Robots.txt directamente desde la misma interfaz:
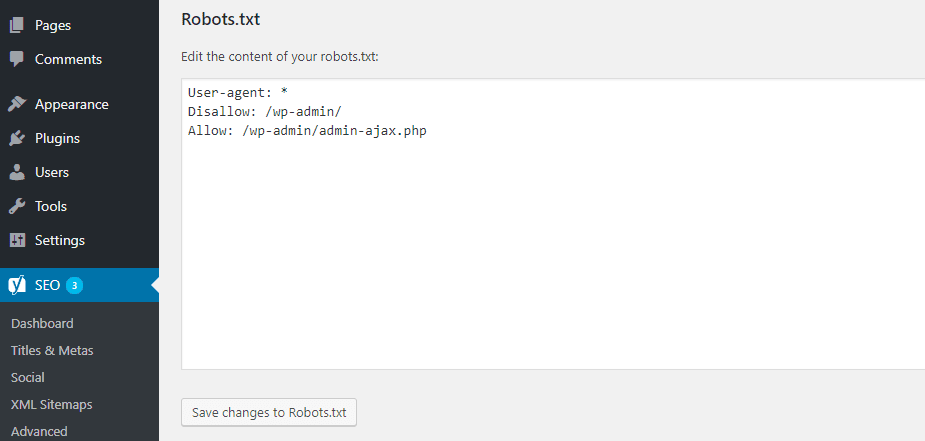
A medida que siga leyendo, veremos más a fondo los tipos de directivas de tutoriales que puede agregar en su archivo robots.txt en un sitio web.
Cómo crear y editar un archivo Robots.txt con All In One SEO
Si esta usando Otros complementos populares Que es algo similar a Yoast: Todo en un paquete de SEO También puede crear y modificar un archivo robots.txt directamente desde la interfaz de la extensión. Todo lo que tienes que hacer es ir a Todo en uno SEO → Administrador de funciones Active la función Robots.txt:
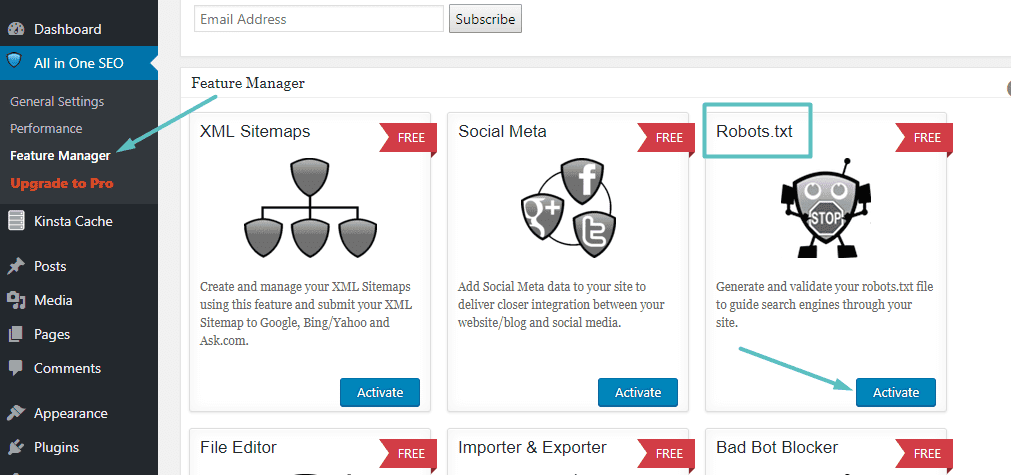
Después de eso, podrá administrar el archivo Robots.txt yendo a Todo en uno SEO → Robots.txt:
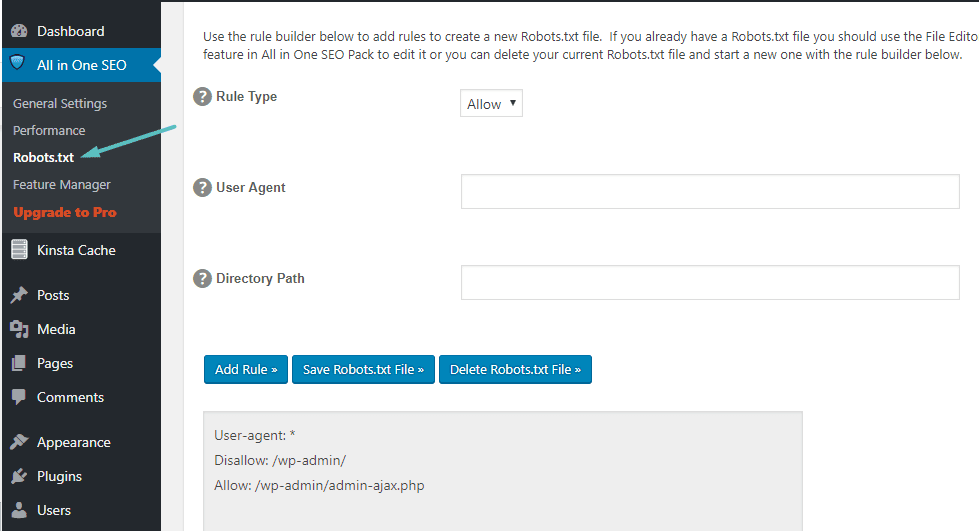
Cómo crear y editar un archivo Robots.txt a través de FTP
Si no está utilizando una extensión de SEO que proporciona acceso a un archivo robots.txt, aún puede crear y administrar su archivo robots.txt a través de SFTP. Primero, use cualquier editor de texto para crear un archivo vacío llamado "robots.txt":
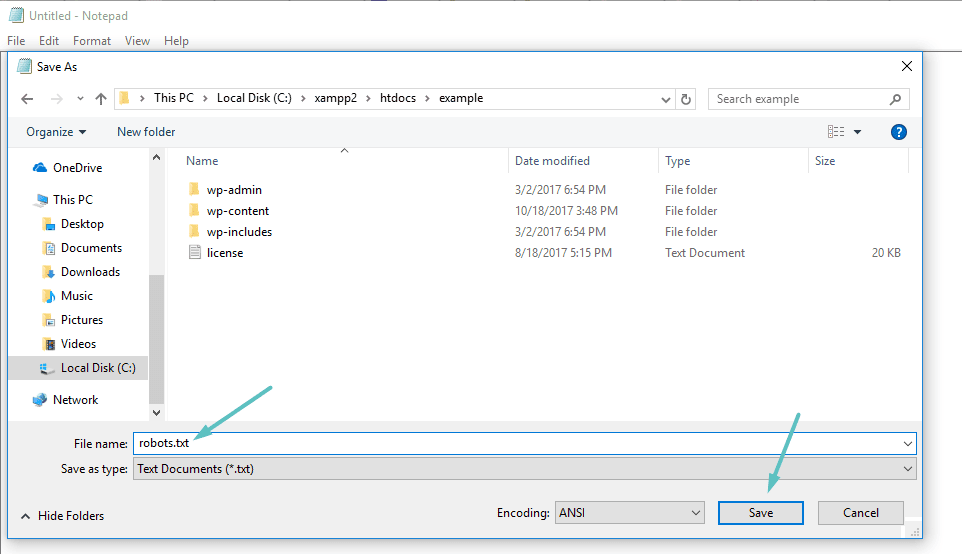
A continuación, conéctese a su sitio a través de SFTP Cargue este archivo en la carpeta raíz de su sitio web. Puede seguir editando su archivo robots.txt editándolo a través de SFTP o cargando nuevas versiones del archivo cada vez.
Agregar un archivo Robots.Txt personalizado a Blogger
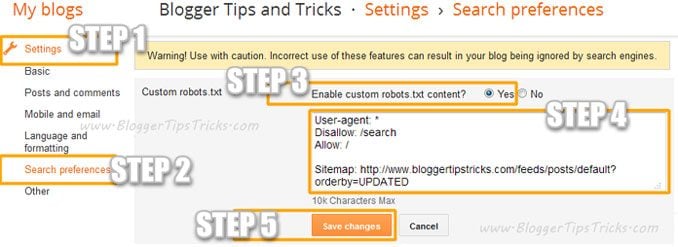
Puede agregar un archivo robots.txt personalizado a Blogger con estos pasos:
- Ve a tu blog.
- Ir Configuración >> Preferencias de búsqueda ›› Rastreadores e indexación ›› Archivos robots.txt personalizados ›› Editar ›› Sí
- Ahora pegue su código robots.txt en el cuadro.
- Haga clic en el botón Guardando cambios.
¿Qué se muestra en el archivo Robots.txt?
Bueno, ahora tiene un archivo robots.txt real en su servidor que puede modificar según sea necesario. Pero, ¿qué haces realmente con este archivo? Bueno, como aprendió en la primera sección, el archivo robots.txt le permite controlar cómo interactúan los bots con los diversos contenidos que se muestran en su sitio. Puedes hacer esto usando dos cosas básicas:
- Agente de usuario Esto le permite dirigirse a rastreadores específicos. agente de usuario Es lo que utiliza un rastreador para identificarse. Con él, puede, por ejemplo, crear una regla que se aplique al rastreador de Bing, pero no al rastreador de Google.
- rechazar Esto le permite indicar a los rastreadores que no accedan a ciertas áreas de su sitio.
También hay una orden Permitir Lo utilizará en situaciones especializadas. Por defecto, está marcado Permitir en todo en su sitio, por lo que no es necesario utilizar el comando Permitir En el 99% de los puestos. Pero es útil cuando no desea permitir que los rastreadores accedan a una carpeta y sus subcarpetas, pero permite el acceso a una subcarpeta específica.
Puede agregar reglas seleccionando primero el agente de usuario al que se debe aplicar la regla y luego especificando qué reglas se deben aplicar usando las dos etiquetas rechazar و Permitir. También hay algunos otros comandos como Demora de rastreo و Mapa del Sitio , pero estos son:
- Es ignorado por la mayoría de los principales rastreadores, o interpretado de formas completamente diferentes (en el caso de Demora de rastreo).
- Se volvieron adicionales debido a herramientas como Google Search Console (en caso de que Mapa del Sitio)
Repasemos algunos casos de uso específicos para mostrarle cómo se pueden usar todos estos comandos juntos.
Cómo usar Robots.txt para bloquear el acceso a todo su sitio
Supongamos que desea evitar que todos los rastreadores accedan a su sitio. Es poco probable que esto suceda en un sitio en ejecución, pero es útil para un sitio en desarrollo. Para hacer esto, agregará este código a su archivo robots.txt:
User-agent: * Disallow: /
¿Qué está pasando en este código?
asterisco * Junto a Agente de usuario Significa "Todos los agentes de usuario. El asterisco es un comodín, lo que significa que estos comandos se aplican a todos los agentes de usuario. La barra indica / ubicado junto a rechazar indica que desea prohibir el acceso a todas las páginas que contengan “tudominio.com/(Esto significa todas las páginas de su sitio).
Cómo usar Robots.txt para evitar que un solo rastreador acceda a su sitio
Cambiemos las cosas. En este ejemplo, fingiremos que no le gusta el hecho de que Bing rastrea sus páginas. Eres fanático del motor de búsqueda de Google y ni siquiera quieres que Bing mire tu sitio. Para evitar que solo Bing rastree su sitio, debe reemplazar el asterisco * B Bingbot:
User-agent: Bingbot Disallow: /
Básicamente, el código anterior indica aplicar una regla rechazar Solo en rastreadores que usan el agente de usuario "Bingbot". Ahora, es poco probable que desee bloquear el acceso desde Bing, pero este escenario es útil si un rastreador específico que no desea está accediendo a su sitio. Este sitio tiene una buena lista de la mayoría de los nombres Agentes de usuario conocido.
Cómo usar Robots.txt para bloquear el acceso a una carpeta o archivo específico
En este ejemplo, supongamos que solo desea bloquear el acceso a un archivo o carpeta específicos (y todas las subcarpetas de esa carpeta). Para aplicar esto a su sitio, digamos que desea bloquear ambos:
- Toda la carpeta wp-admin
- página wp-login.php صفحة
Puede utilizar los siguientes comandos:
User-agent: * Disallow: /wp-admin/ Disallow: /wp-login.php
Cómo usar el archivo Robots.txt para permitir el acceso a un archivo específico en una carpeta que no está permitida
Bueno, ahora digamos que desea bloquear una carpeta completa, pero aún desea permitir el acceso a un archivo específico dentro de esa carpeta. Aquí es donde entra Permitir útil. En realidad, es un proceso viable en su sitio. De hecho, el archivo robots.txt predeterminado se muestra en WordPress Esto es idealmente:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php
Este código impide el acceso a toda la carpeta. / Wp-admin / excepto para el archivo /wp-admin/admin-ajax.php.
Cómo usar Robots.txt para evitar que los bots rastreen los resultados de búsqueda de su sitio
Una de las modificaciones que puede realizar en su sitio es evitar que el rastreador de búsqueda acceda a las páginas de resultados de búsqueda de su sitio. Por defecto, WordPress usa el parámetro de consulta “?s =Muestra los resultados de la búsqueda. Entonces, para evitar el acceso, todo lo que tiene que hacer es agregar la siguiente regla:
User-agent: * Disallow: /?s= Disallow: /search/
Esta puede ser una forma efectiva de detener los errores 404 si encuentra muchos de ellos.
Cómo crear diferentes reglas para diferentes rastreadores en el archivo robots.txt
Hasta ahora, todos los ejemplos han manejado una regla a la vez. Pero, ¿qué sucede si desea aplicar diferentes reglas a diferentes rastreadores? Simplemente debe agregar cada conjunto de reglas en la declaración del agente de usuario de cada rastreador. Por ejemplo, si desea crear una regla que se aplique a todos los rastreadores y otra regla que se aplique a Bingbot Simplemente, puedes hacerlo así:
User-agent: * Disallow: /wp-admin/ User-agent: Bingbot Disallow: /
En este ejemplo, se bloqueará el acceso de todos los rastreadores / Wp-admin , pero Bingbot no podrá acceder a todo su sitio.
Reglas útiles de robots.txt
Aquí hay algunas reglas de robots.txt útiles y comunes:
| مثال | Al Qaeda |
User-agent: * Disallow: / | Impedir el rastreo de todo el sitio web. Tenga en cuenta que, en algunos casos, las URL de un sitio web aún se pueden indexar incluso si no se han rastreado. Nota: esta regla no coincide con los diferentes rastreadores de AdsBot, que deben configurarse explícitamente. |
User-agent: * Disallow: /calendar/ Disallow: /junk/ | Evite el rastreo de un directorio y su contenido agregando una barra inclinada después del nombre del directorio. Tenga en cuenta que no debe usar un archivo robots.txt para bloquear el acceso a contenido privado y le recomendamos que use la autenticación adecuada en su lugar. Las direcciones URL que han sido bloqueadas por robots.txt todavía se pueden indexar sin ser rastreadas y cualquiera puede ver el archivo robots.txt, lo que podría exponer la ubicación del contenido privado que no desea que nadie más vea. |
User-agent: Googlebot-news Allow: / User-agent: * Disallow: / | Permitir el acceso de un solo rastreador |
User-agent: Unnecessarybot Disallow: / User-agent: * Allow: / | Permitir el acceso a todos los rastreadores excepto a uno |
User-agent: * Disallow: /private_file.html | Evite el rastreo de una sola página web insertando la página después de la barra inclinada |
User-agent: Googlebot-Image Disallow: /images/dogs.jpg | Bloquear una imagen específica de Google Photos: |
User-agent: Googlebot-Image Disallow: / | Bloquee todas las imágenes en su sitio web de Google Photos: |
User-agent: Googlebot Disallow: /*.gif$ | Evite el rastreo de archivos de cierto tipo (p. ej., .gif): |
User-agent: * Disallow: / User-agent: Mediapartners-Google Allow: / | Evita el rastreo de todo el sitio, pero muestra anuncios de AdSense en esas páginas y bloquea el acceso de todos los rastreadores web que no sean Mediapartners-Google. Esto oculta las páginas de los resultados de búsqueda, pero el rastreador web Mediapartners-Google aún puede analizar las páginas para determinar qué anuncios mostrar a los visitantes de su sitio web. |
User-agent: Googlebot Disallow: /*.xls$ | Para hacer coincidir las URL que terminan en una cadena específica, puede usar $. Por ejemplo, el ejemplo de código bloquea el acceso a cualquier URL que termine en .xls: |
Pruebe su archivo Robots.txt
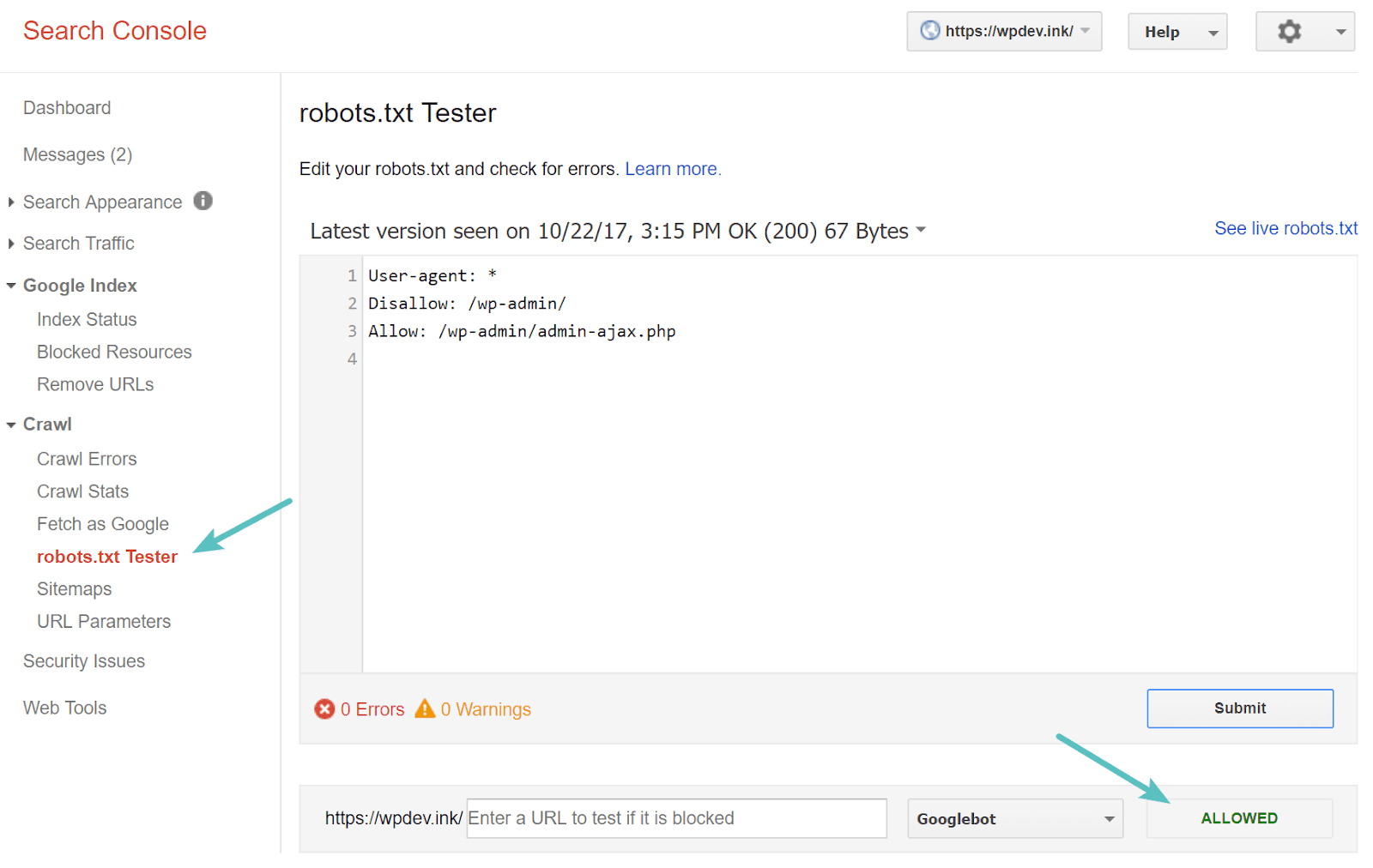
Puede probar su archivo robots.txt en Google Búsqueda consola Para asegurarse de que está configurado correctamente. Simplemente haga clic en su sitio, y dentro "gatear" , toque en "Probador de robots.txt. Luego puede probar el envío de cualquier URL, incluida su página de inicio. Debería ver una marca verde que dice Acceso permitido si todo es rastreable. También puede probar las URL que ha bloqueado para asegurarse de que ya estén bloqueadas o no permitidas.
Cuidado con la lista de materiales UTF-8
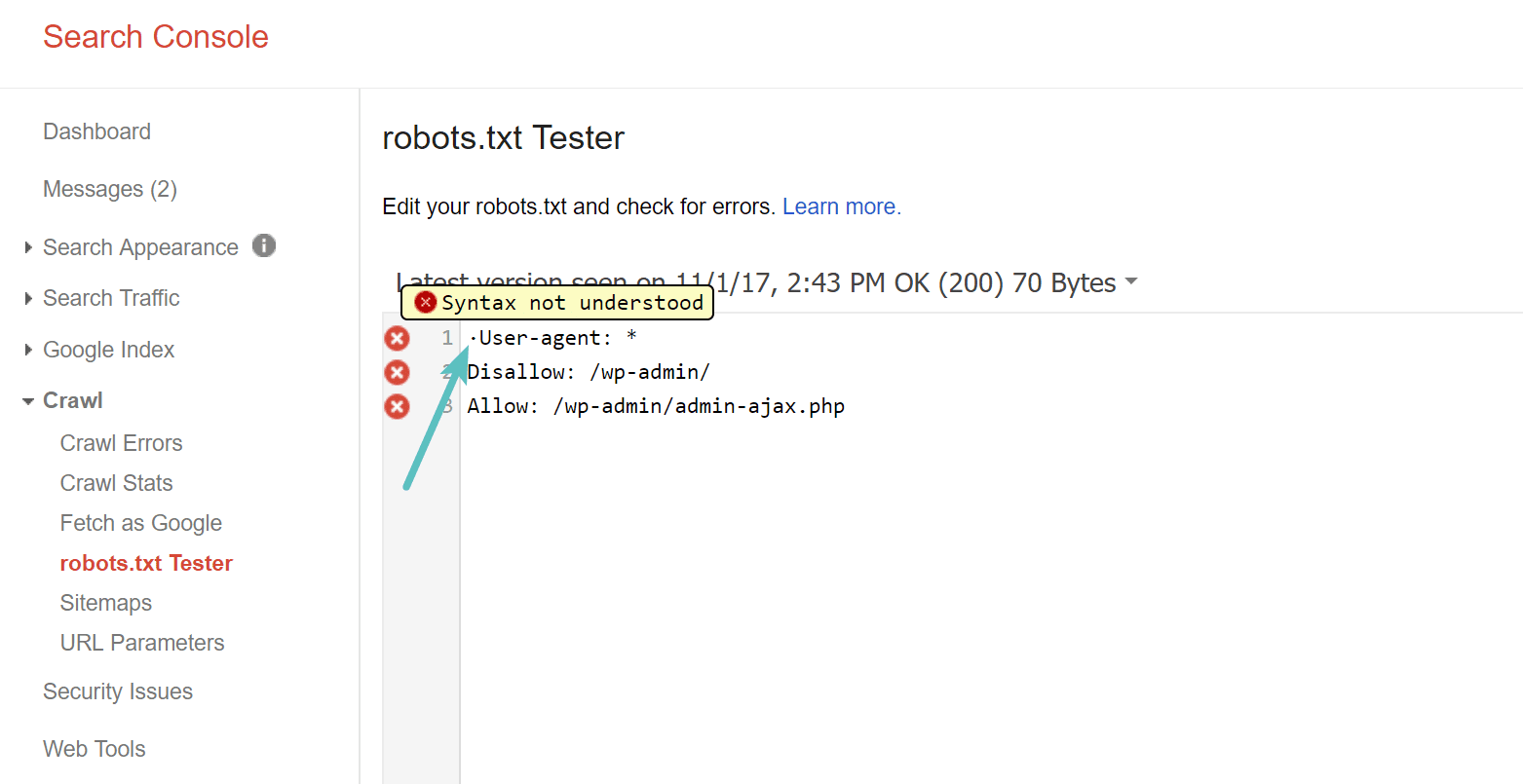
BOM significa marca de orden de bytes y es básicamente un carácter invisible que a veces los editores de texto antiguos y similares agregan a los archivos. Si le sucede a un archivo robots.txt, es posible que Google u otros motores de búsqueda no lo lean correctamente. Es por eso que es importante revisar su archivo para ver si hay errores. Por ejemplo, como se muestra a continuación, nuestro archivo tenía un carácter invisible que resultó en un malentendido de la sintaxis por parte de Google. Esto básicamente invalida por completo la primera línea del archivo robots.txt, ¡lo cual no es bueno! Glenn Gabe contiene excelente articulo Acerca de cómo nació UTF-8 Mata tu SEO.
Googlebot se encuentra principalmente en los Estados Unidos
También es importante no bloquear Googlebot desde los EE. UU., incluso si se dirige a un área local fuera de los EE. UU. Este bot a veces realiza un rastreo local, pero Googlebot se encuentra principalmente en los EE. UU.
¿Qué información agregan los sitios web populares en su archivo robots.txt?
Para proporcionar algo de contexto a los puntos anteriores, así es como algunos de los sitios web más populares usan sus archivos robots.txt.
TechCrunch
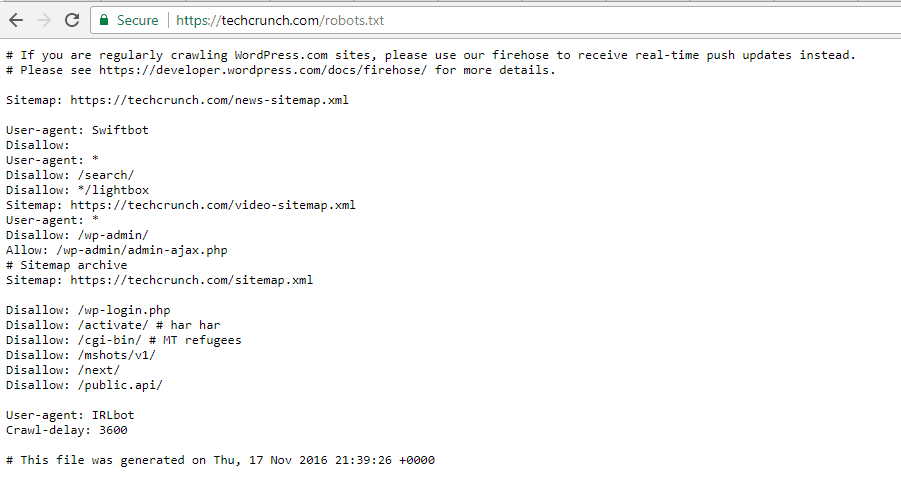
Además de restringir el acceso a varias páginas únicas, el rastreo de:
- / Wp-admin /
- /wp-login.php
Algunos de los rastreadores también tienen restricciones especiales:
- robotveloz
- IRLbot
Si está interesado, IRLbot es un rastreador de un proyecto de investigación. Universidad Texas A & M. ¡Es raro!
La Fundación Obama
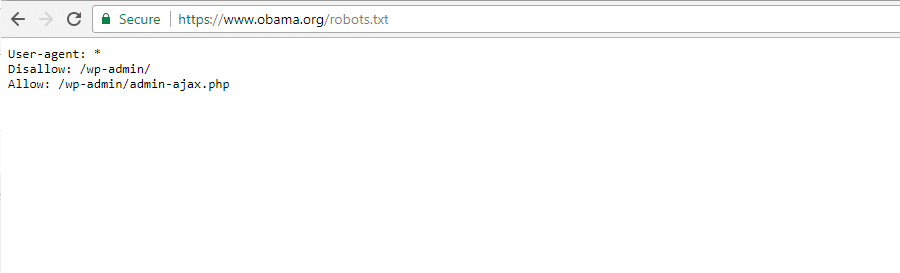
La Fundación Obama no ha realizado adiciones especiales, optando exclusivamente por restringir el acceso a / Wp-admin /.
Angry Birds

Angry Birds tiene la misma configuración predeterminada que The Obama Foundation. No se ha añadido nada especial.
Drift

Finalmente, Drift eligió Seleccionar archivos Sus mapas de sitio en el archivo Robots.txt, pero aparte de eso, deje las mismas restricciones predeterminadas que Angry Birds.
Usando Robots.txt de la manera correcta
Mientras finalizamos esta guía, nos gustaría recordarle una vez más que usar el comando . rechazar No es como usar el signo sin índice. El archivo robots.txt evita el rastreo, pero no necesariamente la indexación. Puede usarlo para agregar reglas específicas para dar forma a cómo interacción del motor de búsqueda y otros rastreadores con su sitio, pero no controlará explícitamente si su contenido es indexable o no.
Para la mayoría Usuarios de WordPress Por lo general, no hay una necesidad urgente de modificar el archivo robots.txt predeterminado. Pero si tiene problemas con un rastreador en particular, o desea cambiar la forma en que los motores de búsqueda interactúan con un complemento o plantilla en particular que está utilizando, es posible que desee agregar sus propias reglas.
Esperamos que haya disfrutado de esta guía y asegúrese de dejar un comentario si tiene más preguntas sobre el uso de su archivo robots.txt en sitio web.







