Недавно мы стали свидетелями ускоренного развития в области искусственного интеллекта, поскольку теперь у нас есть большие возможности анализировать и понимать данные способами, которые были невозможны раньше. Однако это развитие поднимает важные проблемы, касающиеся конфиденциальности и безопасности данных, особенно когда речь идет о личных данных на сайтах социальных сетей.
Одним из последних способов монетизации пользовательских данных являются сделки с компаниями, занимающимися искусственным интеллектом. Но могут ли обычные пользователи что-нибудь сделать для защиты своих данных и контента?
В этой статье мы проанализируем влияние искусственного интеллекта на безопасность ваших учетных записей в социальных сетях и обсудим, что вы можете сделать, чтобы защитить свою конфиденциальность. Мы рассмотрим потенциальные проблемы и проблемы, с которыми сталкиваются персональные данные на платформах социальных сетей, и дадим несколько советов о том, как эффективно бороться с этими воздействиями. Проверять Искусственный интеллект и риски конфиденциальности: защита ваших данных в автоматизированном мире.

Платформы социальных сетей заключили соглашения с компаниями, занимающимися искусственным интеллектом
Использование данных социальных сетей для обучения генеративных моделей искусственного интеллекта было спорным шагом, но это, похоже, не мешает компаниям социальных сетей раздавать пользовательские данные в обмен на больше денег.
Meta уже использует данные своих социальных сетей для обучения генеративных моделей искусственного интеллекта, о которых будет объявлено на Meta Connect в 2023 году. Сюда входят Meta AI и такие функции, как Создавайте плакаты с помощью искусственного интеллекта В Ватсап.
Как заявил Майк Кларк, директор по управлению продуктами Meta, в сообщении на... Мета-отдел новостей:
«Общедоступные публикации из Instagram и Facebook, включая изображения и текст, были частью данных, используемых для обучения генеративных моделей искусственного интеллекта, лежащих в основе функций, которые мы анонсировали на Connect».
Эта тенденция, похоже, не замедлится в 2024 году. По данным... РейтерReddit достиг соглашения с Google, чтобы сделать контент платформы социальных сетей доступным для обучения моделей искусственного интеллекта.
Подтвердить отправку Реддит С-1 В отношении первичного публичного размещения акций, которое было подано 22 февраля 2024 года, компания изучает лицензионные сделки. В представлении указано:
«Данные Reddit являются ключевой частью создания современных технологий искусственного интеллекта и многих моделей LLM. «Мы считаем, что обширная коллекция диалоговых данных и знаний Reddit будет продолжать играть роль в обучении и совершенствовании моделей LLM».
В нем уточняется, что Reddit «находится на ранних стадиях предоставления третьим сторонам возможности лицензировать доступ к исследованиям, анализу и отображению исторических данных и данных в реальном времени с нашей платформы» для обучения LLM.
Хотя Meta и Reddit — два крупнейших имени в социальных сетях, они не единственные платформы, использующие данные социальных сетей для обучения искусственного интеллекта. Согласно отчету, опубликованному 404 Медиа, Tumblr и WordPress.com готовятся продавать пользовательские данные Midjourney и OpenAI.
Можете ли вы запретить социальным платформам продавать данные вашей учетной записи для обучения искусственного интеллекта?
Скорее всего, если вы используете Facebook, Instagram, Reddit, Tumblr или WordPress.com, ваш общедоступный контент уже использовался для обучения вашей модели LLM.
Например, если вы используете инструмент поиска для Washington Post Чтобы увидеть, какие веб-сайты были включены в набор данных Google C4, который использовался в рамках учебного упражнения. Gemini, вы увидите, что Reddit.com представляет 7.9 миллиона токенов.
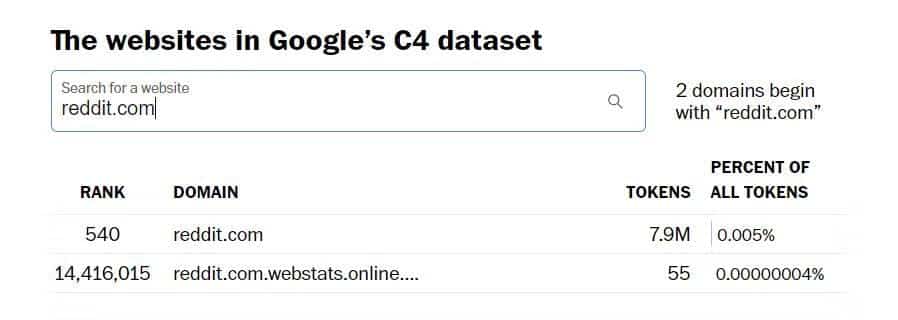
Tumblr.com имеет более 1.6 миллиона иконок. Мой небольшой веб-сайт, использующий WordPress.com, имеет 14000 XNUMX токенов, поэтому небольшие личные блоги, вероятно, были включены в набор данных.
А учитывая продолжающиеся сделки между компаниями, занимающимися искусственным интеллектом, и компаниями, занимающимися социальными сетями, лицензионные соглашения будут означать, что эти данные будут активно продаваться, а не просто удаляться из сети.
Но когда дело доходит до будущей обработки, что вы можете сделать для защиты своих данных? Мета предоставила модель для Права субъектов данных генеративного ИИ Это позволяет вам возражать или ограничивать обработку ваших личных данных третьими лицами для обучения генеративных моделей искусственного интеллекта Meta.
В этой форме вы можете делать запросы относительно вашей личной информации от третьих лиц, которая используется для обучения генеративных моделей искусственного интеллекта Meta. В общем, личная информация — это информация о вас. Примеры включают ваше имя, домашний адрес, номер телефона или адрес электронной почты. Информация от третьих лиц включает в себя информацию, общедоступную в Интернете, и лицензионную информацию, которая принадлежит кому-то другому и на использование которой Meta дала разрешение.
Стоит отметить, что эта опция не позволяет вам возражать против сторонней обработки ваших данных компанией Meta для обучения ее генеративного ИИ. Более того, когда я отправил заявку на возражение против использования моих личных данных с помощью формы, в службе поддержки меня попросили доказать, что моя личная информация действительно появляется в результатах генеративного ИИ Meta.
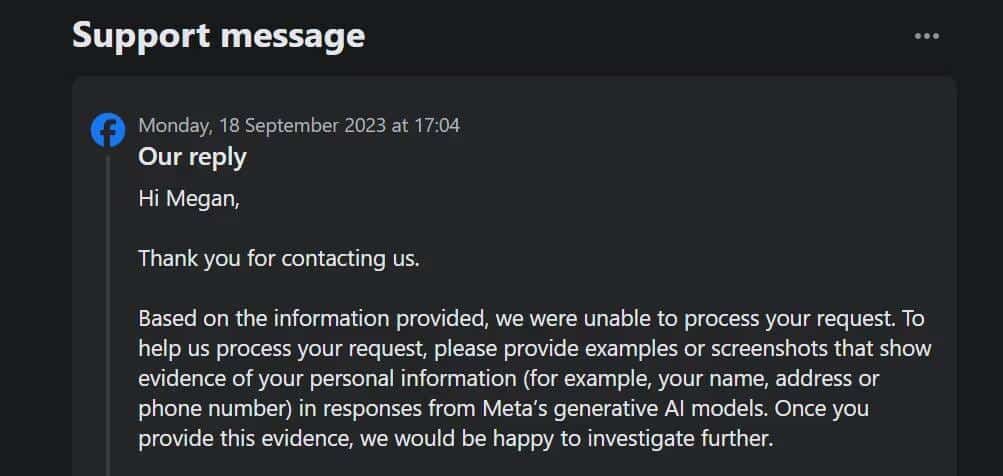
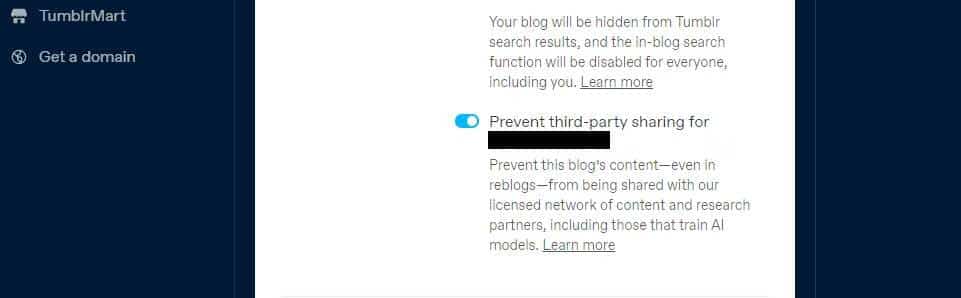
Tumblr также представил возможность отказаться от обмена контентом вашего общедоступного блога с третьими лицами с помощью настроек вашего блога. Вы можете найти его в настройках, нажав на свой блог и прокрутив вниз до Настройки видимости. тогда выбирай Запретите третьим лицам делиться вашим блогом.
Когда дело доходит до такой платформы, как Instagram, вы можете попробовать преобразовать свою учетную запись в Инстаграм в приват Чтобы предотвратить использование ваших данных. Это не гарантирует, что ваши данные не будут использованы, но поскольку интеллектуальный анализ данных для LLM, похоже, ориентирован на общедоступные данные, это может быть потенциальной гарантией.
Вы также можете сделать свою учетную запись X (Twitter) конфиденциальной, но, опять же, это всего лишь потенциальная мера предосторожности, которая не гарантирует, что ваши данные останутся конфиденциальными.
Он предложил Совместное заявление Многие национальные комиссары по информации и эксперты по всему миру разработали некоторые меры для людей, стремящихся снизить риски конфиденциальности, вызванные сбором данных компаниями, занимающимися искусственным интеллектом. Консультация включает в себя:
- Прочтите условия и политику конфиденциальности веб-сайта, чтобы узнать, как передается ваша личная информация.
- Ограничьте информацию, которую вы публикуете в Интернете, особенно конфиденциальную информацию.
- Вы должны управлять настройками конфиденциальности.
- Думайте о долгосрочной перспективе об информации, которой вы делитесь в Интернете.
- Свяжитесь с компанией социальной сети или с веб-сайтом, если вы считаете, что ваши данные были переданы неправильно. Если вы не удовлетворены их ответом, подайте жалобу в соответствующий орган по защите данных.
Ты тоже можешь Удалить некоторую информацию в Интернете Если вас не устраивает доступ к нему третьих лиц, даже если общедоступная информация в ваших личных аккаунтах уже могла быть скопирована.
К сожалению, мы, обычные пользователи, мало что можем сделать для защиты наших данных от компаний, занимающихся искусственным интеллектом. Настоящий контроль над этой информацией, скорее всего, будет возможен только с помощью регулирующих органов. Теперь вы можете просмотреть Являются ли человеческие возможности или искусственный интеллект более эффективными в обнаружении технологий дипфейков?.