Инструменты командной строки, такие как grep и ack-grep, хорошо подходят для поиска в текстовых файлах шаблонов, соответствующих регулярному выражению и разделителю. Но пробовали ли вы когда-нибудь использовать эти утилиты для поиска шаблонов в файле PDF? Ладно, нет! Вы не получите никакого результата, потому что эти инструменты не могут Искать в PDF-файлах. Они читают только простые текстовые файлы.

pdfgrep, как следует из названия, представляет собой небольшой инструмент командной строки, который позволяет искать текст в файле PDF, не открывая файл. Процесс поиска безумно быстр - быстрее, чем процесс поиска, предлагаемый почти всеми программами для чтения PDF. Большая разница между grep и pdfgrep заключается в том, что pdfgrep запускается на страницах, а grep - на строках. Он также печатает одну строку несколько раз, если в этой строке встречается более одного предложения. Давайте посмотрим, как именно использовать инструмент.
Установка
Для Ubuntu и других дистрибутивов Linux на основе Ubuntu это очень просто:
sudo apt install pdfgrep
Для других дистрибутивов, просто предоставив pdfgrep В качестве входных данных для диспетчера пакетов, который необходимо получить и установить. Вы также можете проверить страницу проекта по адресу GitLab, если вы хотите поэкспериментировать со своим кодом.
Запустить тест
Теперь, когда инструмент установлен, приступим к тесту. Команда pdfgrep принимает вид:
pdfgrep [OPTION...] PATTERN [FILE...]
- OPTION - это список дополнительных атрибутов, передаваемых команде, таких как -i или -ignore-case, который игнорирует как случай различия между заданным обычным стилем, так и один раз, когда он соответствует в файле.
- ШАБЛОН - это просто расширенное регулярное выражение.
- ФАЙЛ - это просто имя файла, если он находится в том же рабочем каталоге, или путь к файлу.
Я выполнил команду из официальной документации по Python 3.6. Следующее изображение является результатом.
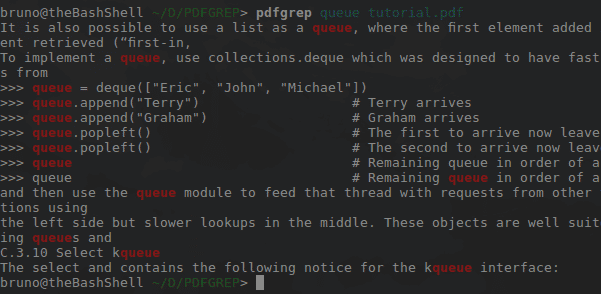
Красной линией отмечены все места, где появилось слово «очередь». Передайте -i в качестве параметра команды для слов, содержащих слово «Очередь». Помните, что регистр не имеет значения, если -i передается как опция.
Дополнительно
pdfgrep имеет большое количество интересных возможностей для использования. Однако я остановлюсь только на некоторых из них.
Полный список поддерживаемых опций можно найти на страницах руководства или на pdfgrep онлайн-руководство. Не забывайте, что pdfgrep может искать несколько файлов одновременно, если вы работаете с некоторыми незакрепленными файлами. Цвет выделения по умолчанию можно изменить, изменив переменную среды GREP_COLORS.
Заключение
В следующий раз, когда вы подумаете об открытии PDF-файла для поиска чего-либо. Вы можете рассмотреть возможность использования pdfgrep. Инструмент пригодится и сэкономит ваше время.