Python ganhou reputação por sua versatilidade e inclusão de muitas ferramentas, tornando-se a linguagem de escolha para ciência de dados. Incentivou muitas bibliotecas a inovar neste campo. Para melhorar suas habilidades e explorar novas oportunidades, é importante manter-se atualizado com as ferramentas emergentes e recém-desenvolvidas.
A ciência de dados tornou-se um campo cada vez mais importante nos últimos anos, em parte porque novas ferramentas poderosas estão disponíveis para facilitar a coleta e análise de dados. Existem muitas ferramentas de ciência de dados disponíveis em Python, que podem ser usadas para executar uma variedade de tarefas, incluindo a criação de gráficos, previsões e visualizações prospectivas. Verificar Maneiras de ficar por dentro das últimas tendências em ciência de dados.

1. ConnectorX: Simplifique o upload de dados
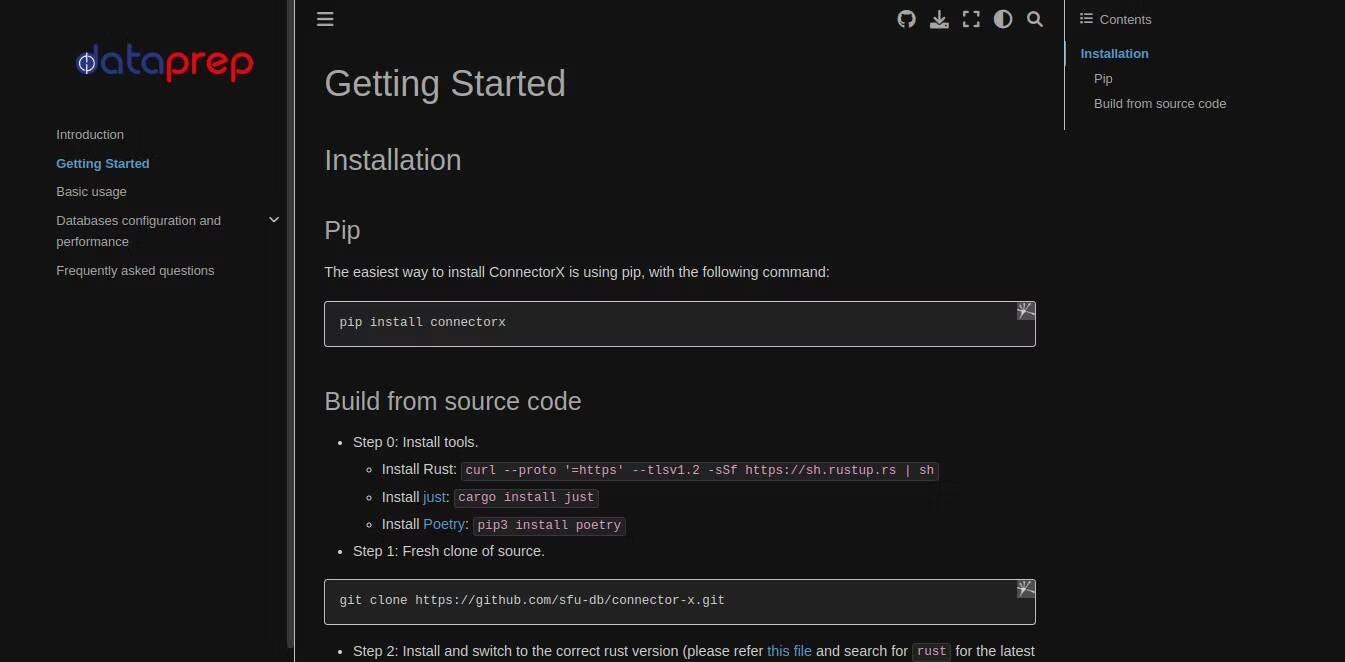
Embora a maioria dos dados resida em bancos de dados, os cálculos geralmente ocorrem fora deles. No entanto, mover dados de e para bancos de dados durante o trabalho real pode causar lentidão.
Levante-se ConectorX Ele carrega dados de bancos de dados em muitas ferramentas populares de análise de dados em Python e mantém as coisas rápidas e suaves, reduzindo a quantidade de trabalho que precisa ser feito.
O ConnectorX usa a biblioteca de linguagem de programação Rust em seu núcleo. Isso permite melhorias, como a capacidade de carregar da fonte de dados em paralelo com o particionamento. Dados em um banco de dados PostgreSQL, por exemplo, você pode carregá-los dessa forma especificando a coluna da seção.
O IConnectorX também oferece suporte à leitura de dados de vários bancos de dados, incluindo MySQL/MariaDB, SQLite, Amazon Redshift, Microsoft SQL Server, Azure SQL e Oracle.
Você pode converter resultados em DataFrames Pandas ou PyArrow, ou encaminhá-los para Modin, Dask ou Polars usando PyArrow.
2. DuckDB: habilitar cargas de trabalho de consulta analítica
يستخدم DuckDBName Armazenamento vertical de dados e otimização de cargas de trabalho de consulta analítica de longa duração. Fornece todos os recursos esperados de um banco de dados tradicional, incluindo transações ACID.
Além disso, você pode configurá-lo em um ambiente Python com um comando instalação de pip Um, eliminando a necessidade de configurar um conjunto de aplicativos separado.
O DuckDB ingere dados no formato CSV, JSON ou Parquet. O DuckDB melhora a eficiência dividindo os bancos de dados resultantes em arquivos físicos separados de acordo com chaves como ano e mês.
Quando o DuckDB é usado para consultas, ele se comporta como um banco de dados relacional baseado em SQL normal, mas com recursos adicionais, como amostragem de dados aleatórios e geração de função analítica (função de quadro).
Além disso, o DuckDB fornece formatos úteis, como pesquisa de texto completo, importação/exportação do Excel, conexões diretas com SQLite e PostgreSQL, exportação de arquivo Parquet e suporte para muitos formatos e tipos de dados geoespaciais populares. Verificar Como funcionam as tabelas temporárias do SQL Server?.
3. Optimus: Simplifique o processamento de dados

Limpar e preparar dados para projetos centrados em DataFrame pode ser uma tarefa estressante que requer muita eficiência. Optimus É um kit de ferramentas abrangente projetado para carregar, explorar, limpar e reescrever dados em várias fontes de dados.
A Optimus pode usar Pandas, Dask, CUDF (e Dask + CUDF), Vaex ou Spark como mecanismo de dados primário. Você pode carregar e salvar de volta para Arrow, Parquet, Excel e várias fontes de banco de dados populares ou formatos de arquivo simples como CSV e JSON.
Semelhante à API de processamento de dados do Optimus Pandas, mas fornece mais conectores .linhas() و colunas(). Esses conectores facilitam muito a execução de várias tarefas.
Por exemplo, você pode classificar ou filtrar a estrutura de gerenciamento de dados com base nos valores da coluna, alterar os dados usando critérios específicos ou limitar as operações com base em determinadas condições. Além disso, o Optimus inclui assistentes projetados para lidar com tipos de dados comuns do mundo real, como endereços de e-mail e URLs.
É importante perceber que o Optimus está atualmente em desenvolvimento ativo e seu último lançamento oficial foi em 2020. Como resultado, pode estar menos atualizado em comparação com outros componentes da sua coleção. Verificar Aprenda análise de dados gratuitamente: os melhores sites ao redor.
4. Polars: estrutura de gerenciamento de dados acelerada

Se você está trabalhando com estruturas de gerenciamento de dados e está frustrado com as limitações de desempenho do Pandas, Polares É uma excelente solução. Esta biblioteca de estrutura de dados para Python fornece uma sintaxe conveniente como Pandas.
Ao contrário do Pandas, o Polars usa uma biblioteca escrita em Rust que expande os recursos do seu dispositivo. Você não precisa usar sintaxe especial para aproveitar os recursos de aprimoramento de desempenho, como processamento paralelo ou SIMD.
Mesmo operações simples como a leitura de um arquivo CSV são mais rápidas. Além disso, o Polars fornece modos de execução avançados e completos, permitindo a execução imediata de consultas ou adiamento conforme necessário.
Ele também fornece uma API de streaming para lidar com consultas incrementais, embora esse recurso ainda não esteja disponível para todas as funcionalidades. Os desenvolvedores Rust também podem criar seus próprios complementos Polars usando pyo3.
5. Snakemake: automatize fluxos de trabalho de ciência de dados

A configuração de fluxos de trabalho de ciência de dados apresenta muitos desafios diversos, e garantir consistência e previsibilidade pode ser mais difícil. ele trata fazer cobra Essa limitação ocorre ao automatizar as configurações de análise de dados no Python, garantindo resultados consistentes para todos.
Muitos dos projetos atuais de ciência de dados são baseados no Snakemake. À medida que os fluxos de trabalho da ciência de dados ficam mais complexos, automatizá-los com o Snakemake é útil.
O fluxo de trabalho do Snakemake é semelhante ao GNU. Você pode especificar os resultados desejados usando regras que definem a entrada, a saída e os comandos necessários. Você pode criar regras de fluxo de trabalho multiencadeadas para aproveitar o processamento paralelo.
Além disso, os dados de configuração podem se originar de arquivos JSON/YAML. Os fluxos de trabalho também permitem definir funções para transformar os dados usados nas regras e registrar as ações realizadas em cada etapa.
A Snakemake projeta trabalhos para serem portáteis e implantáveis em ambientes gerenciados por Kubernetes ou plataformas de nuvem selecionadas, como Google Cloud Life Sciences ou Tibanna na AWS.
Você pode congelar fluxos de trabalho para usar um conjunto granular de pacotes, e a execução de fluxos de trabalho pode armazenar testes de unidade criados com eles. Para arquivamento de formato longo, você pode armazenar fluxos de trabalho como arquivos zip. Verificar Data Ethics: O código de conduta que todo cientista de dados deve seguir.
Ferramentas de ciência de dados incomparáveis para Python
Ao adotar essas ferramentas de ciência de dados mais recentes, você pode aumentar sua produtividade, expandir seus recursos e embarcar em emocionantes jornadas orientadas por dados. No entanto, lembre-se de que o cenário da ciência de dados está evoluindo. Para ficar à frente, continue explorando, experimentando e se adaptando a novas ferramentas e tecnologias que estão surgindo neste campo em constante mudança. Você pode ver agora Como se tornar um especialista em entrada de dados.