Bereiden Robots.txt .-bestand Een van de eenvoudigste bestanden op een website, maar ook eentje die voor veel chaos kan zorgen. Slechts één letter die niet op zijn plaats is, kan veel maken SEO-problemen U heeft en zult voorkomen dat zoekmachines toegang krijgen tot belangrijke inhoud op uw site.
Heb je ooit gehoord van de term Robots.txt en vroeg je je af hoe je deze op een website kunt gebruiken? De meeste websites hebben een aangepast Robots.txt-bestand, maar dat betekent niet dat de meeste webmasters Ze begrijpen hoe ze ermee om moeten gaan.
In deze thread hopen we daar verandering in te brengen door een diepgaande gids te geven over het Robots.txt-bestand, en hoe u de toegang van zoekmachines tot uw website kunt controleren en beperken.

Aan het einde van dit artikel kunt u vragen beantwoorden als:
- Wat is een Robots.txt-bestand?
- Hoe helpt een Robots.txt-bestand mijn website?
- Hoe voeg ik Robots.txt toe aan WordPress?
- Welke soorten regels kan ik in Robots.txt plaatsen?
- Hoe kan ik een robots.txt-bestand testen?
- Hoe implementeren grote WordPress-sites een Robots.txt-bestand?
Er zijn veel details die moeten worden behandeld, dus laten we beginnen!
Wat is een Robots.txt-bestand?
Voordat we het hebben over het Robots.txt-bestand op zich, is het belangrijk om te definiëren wat Robots in dit geval betekent. Robots zijn elke vorm vancrawlersdie websites bezoekt. Het meest voorkomende voorbeeld zijn crawlers van zoekmachines. Dit mechanisme kruipt over het web om zoekmachines zoals Google te helpen bij het indexeren en rangschikken van miljarden pagina's op internet.
Dus bots zijn over het algemeen een goede zaak voor internet... of in ieder geval een noodzakelijke zaak. Maar dat betekent niet noodzakelijkerwijs dat jij of een van de andere webmasters wil dat deze bots zonder enige vorm van beperking overal heen gaan.
De wens om te bepalen hoe webcrawlers omgaan met websites, leidde halverwege de jaren negentig tot de creatie van de botuitsluitingsstandaard. Robots.txt-bestand is de praktische keuze voor deze standaard - het stelt u in staat om te bepalen hoe deelnemende bots omgaan met uw site. U kunt de crawler volledig blokkeren, de toegang tot bepaalde delen van uw site beperken en meer.
Het deel "participatie" is wel belangrijk. Een robots.txt-bestand kan een bot niet dwingen zijn instructies op te volgen. En kwaadwillende bots kunnen het robots.txt-bestand negeren. Bovendien negeren gerenommeerde organisaties enkele van de opdrachten die ze aan het Robots.txt-bestand kunnen toevoegen. Google negeert bijvoorbeeld alle regels die u aan uw robots.txt-bestand toevoegt over Het aantal keren bezocht door kruipende bots. Als je veel problemen hebt met bots, kan een beveiligingsoplossing zoiets zijn: Cloudflare of Sucuri bruikbaar.
Waarom zou je om je robots.txt-bestand geven?
Voor de meesten Webmasters De voordelen van een overzichtelijk robots.txt-bestand vallen in twee categorieën:
- Optimaliseer de crawlbronnen voor zoekmachines door hen te vertellen geen tijd te verspillen aan pagina's die u niet wilt indexeren. Dit helpt ervoor te zorgen dat zoekmachines zich concentreren op het crawlen van de pagina's die u het meest interesseren.
- Optimaliseer uw servergebruik door bots te blokkeren die bronnen verspillen.
Het bestand Robots.txt gaat niet over het bepalen welke pagina's worden geïndexeerd door zoekmachines
Het bestand Robots.txt is geen onfeilbare manier om te bepalen welke pagina's door zoekmachines worden geïndexeerd. Als het uw primaire doel is om te voorkomen dat bepaalde pagina's worden opgenomen in de resultaten van zoekmachines, is de juiste aanpak het gebruik van meta-element noindex Of een andere vergelijkbare directe methode.
Dit komt omdat uw Robots.txt-bestand zoekmachines niet rechtstreeks vertelt om inhoud niet te indexeren - het vraagt hen alleen om het niet te crawlen. Hoewel Google geen gebieden crawlt die zijn gemarkeerd als niet-gecrawld vanuit uw site, heeft Google zelf zegt dat Als een externe site linkt naar een pagina die u uitsluit via uw Robots.txt-bestand, kan Google die pagina nog steeds indexeren.
Robots.txt-richtlijnen zijn mogelijk niet compatibel met alle zoekmachines
De instructies in robots.txt-bestanden kunnen geen specifiek gedrag op de website door de crawler afdwingen, omdat het de crawler is die beslist of deze instructies al dan niet worden opgevolgd. Hoewel Googlebot en andere gerenommeerde webcrawlers de robots.txt-richtlijnen volgen, doen andere crawlers dat misschien niet. Dus als u informatie wilt beschermen tegen webcrawlers, is het beter om andere blokkeermethoden te gebruiken, zoals het beveiligen van privébestanden op de server met een wachtwoord.
Een Robots.txt-bestand maken en bewerken
WordPress maakt standaard automatisch een standaard robots.txt-bestand voor uw site. Dus zelfs als u niets doet, zou uw site al het standaard robots.txt-bestand moeten hebben. U kunt testen of dit het geval is door "/robots.txtaan het einde van uw domeinnaam. Er wordt bijvoorbeeld weergegeven "https://www.dz-techs.com/robots.txtHet robots.txt-bestand dat we hier bij Dz Techs gebruiken:
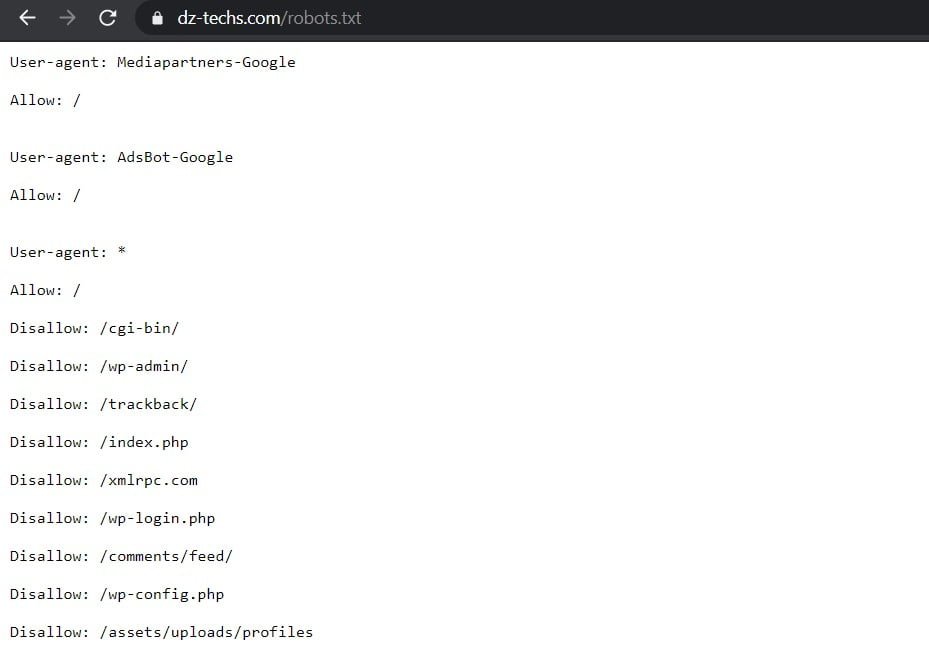
Aangezien het bestand standaard is, kunt u het niet rechtstreeks wijzigen. Als u uw robots.txt-bestand wilt wijzigen, moet u een aangepast bestand op uw server maken dat u naar behoefte kunt wijzigen. Hier zijn drie eenvoudige manieren om dat te doen...
Een Robots.txt-bestand maken en bewerken met Yoast SEO
Als u De beroemde toevoeging Yoast SEO U kunt rechtstreeks vanuit de Yoast-interface een robots.txt-bestand maken (en later bewerken). Voordat u toegang krijgt tot deze optie, moet u inschakelen Geavanceerde Yoast SEO-functies Door naar te gaan SEO → Dashboard → Functies en schakel de schuifregelaar naast Geavanceerde instellingenpagina's:
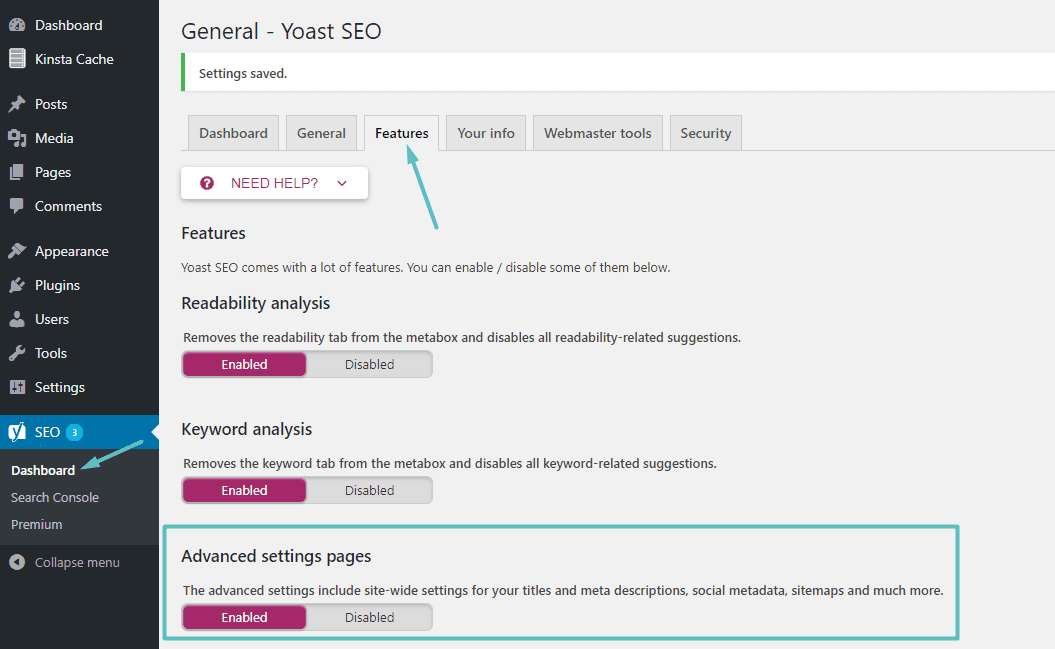
Nadat u het hebt ingeschakeld, kunt u navigeren naar: SEO → Hulpmiddelen en klikken op Bestandseditor:
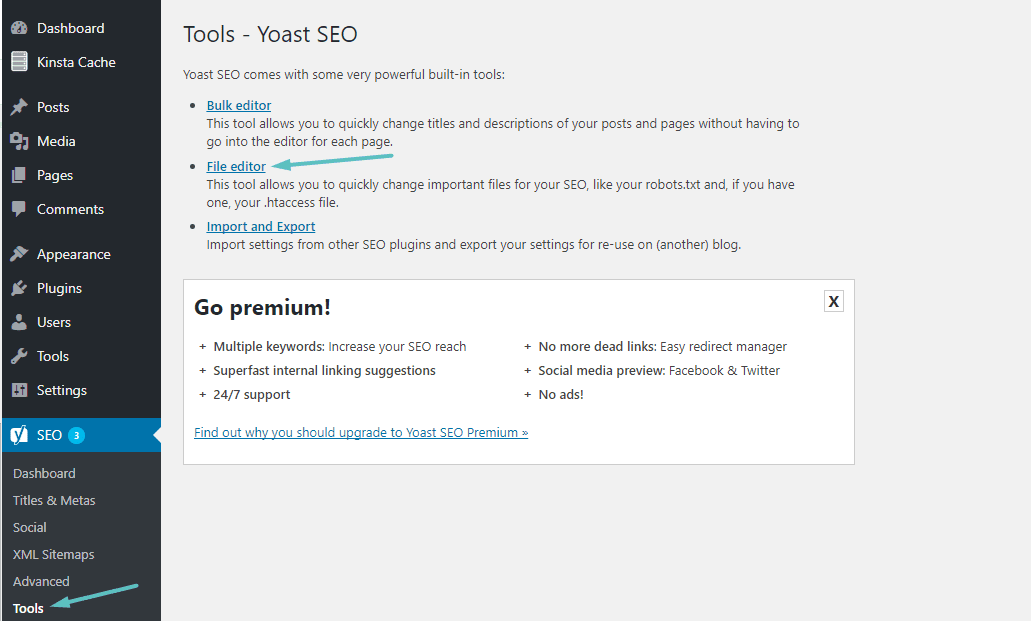
Ervan uitgaande dat de website niet echt een Robots.txt-bestand heeft, geeft Yoast je een optie Maak een robots.txt-bestand:
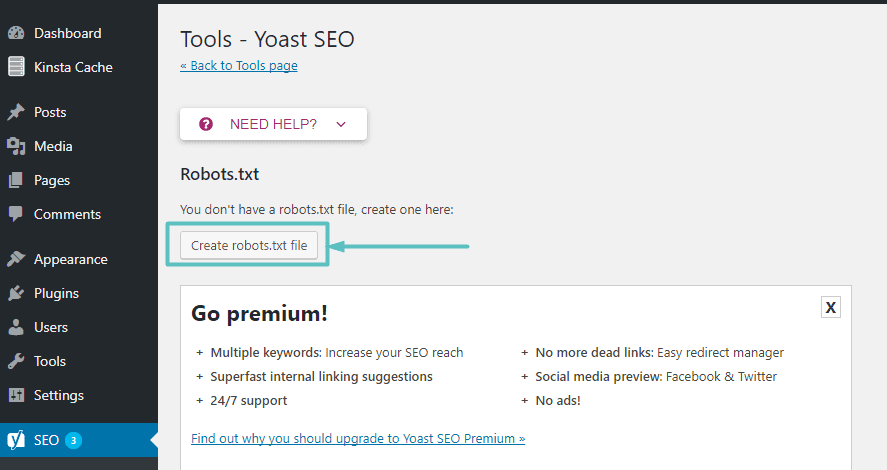
Zodra u op deze knop klikt, kunt u de inhoud van het Robots.txt-bestand rechtstreeks vanuit dezelfde interface bewerken:
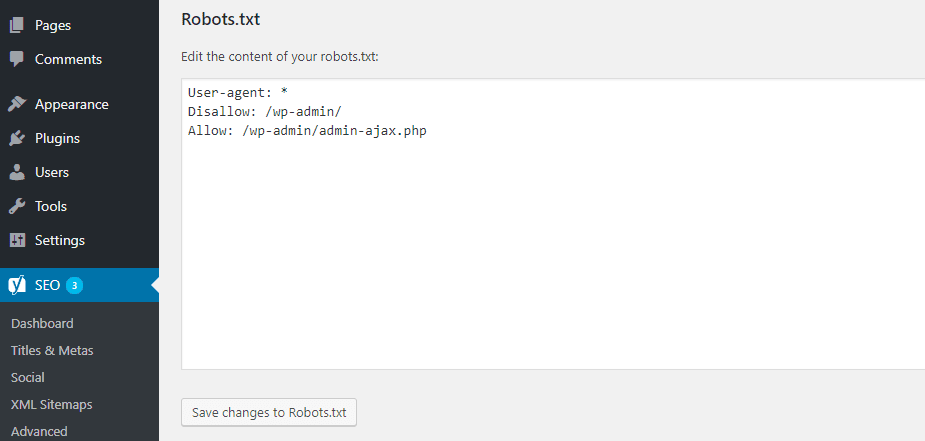
Terwijl u verder leest, zullen we verder kijken naar de soorten instructierichtlijnen die u kunt toevoegen aan uw robots.txt-bestand op een website.
Een Robots.txt-bestand maken en bewerken met All In One SEO
Als u Andere populaire add-ons Wat enigszins lijkt op Yoast: All in One SEO Pack U kunt ook rechtstreeks vanuit de extensie-interface een robots.txt-bestand maken en wijzigen. Het enige wat je hoeft te doen is naar Alles in één SEO → Functiebeheer Activeer de Robots.txt-functie:
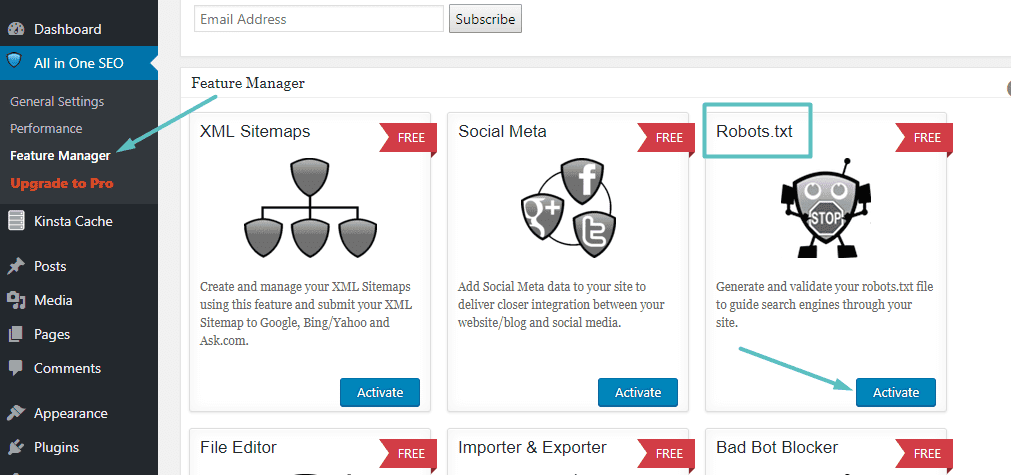
Daarna kunt u het Robots.txt-bestand beheren door naar: Alles in één SEO → Robots.txt:
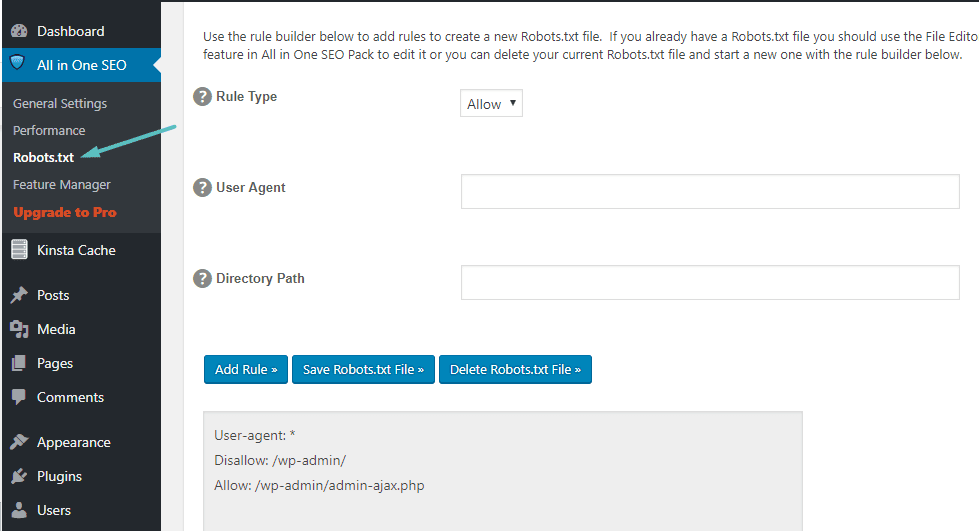
Een Robots.txt-bestand maken en bewerken via FTP
Als u geen SEO-plug-in gebruikt die toegang geeft tot een robots.txt-bestand, kunt u uw robots.txt-bestand nog steeds maken en beheren via SFTP. Gebruik eerst een willekeurige teksteditor om een leeg bestand met de naam "robots.txt" te maken:
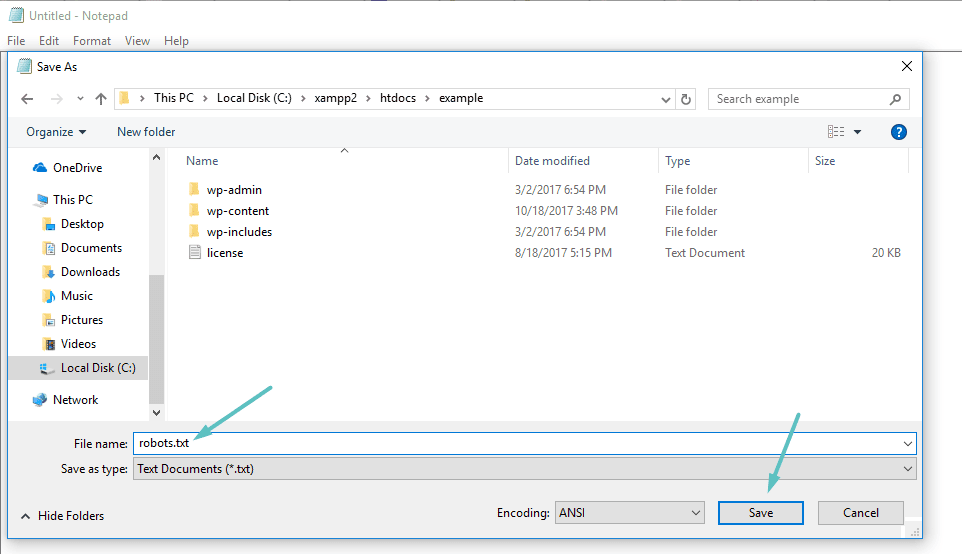
Maak vervolgens verbinding met uw site via SFTP Upload dit bestand naar de hoofdmap van uw website. U kunt uw robots.txt-bestand verder bewerken door het via SFTP te bewerken of door elke keer nieuwe versies van het bestand te uploaden.
Voeg een aangepast Robots.Txt-bestand toe aan Blogger
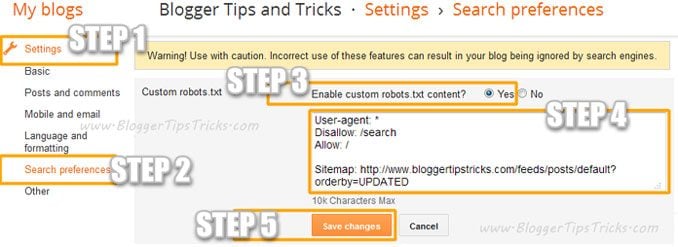
Met deze stappen kun je een aangepast robots.txt-bestand aan Blogger toevoegen:
- Ga naar je blog.
- Ga naar Instellingen >> Zoekvoorkeuren ›› Crawlers en indexeren ›› Custom robots.txt ›› Bewerken ›› Ja
- Plak nu uw robots.txt-code in het vak.
- Klik op de knop Wijzigingen opslaan.
Wat wordt weergegeven in het bestand Robots.txt?
Welnu, u heeft nu een echt robots.txt-bestand op uw server dat u naar behoefte kunt wijzigen. Maar wat doe je eigenlijk met dit bestand? Zoals je in de eerste sectie hebt geleerd, kun je met het robots.txt-bestand bepalen hoe bots omgaan met de verschillende inhoud die op je site wordt weergegeven. U kunt dit doen met behulp van twee basisdingen:
- Gebruikersagent Hiermee kunt u specifieke crawlers targeten. gebruikersagent Het is wat een crawler gebruikt om zichzelf te identificeren. Hiermee kun je bijvoorbeeld een regel maken die van toepassing is op de Bing-crawler, maar niet op de Google-crawler.
- weigeren Hiermee kunt u crawlers vertellen dat ze bepaalde delen van uw site niet mogen openen.
Er is ook een bestelling Allow Je gebruikt het in gespecialiseerde situaties. Standaard is het gemarkeerd als Allow op alles op uw site, dus het is niet nodig om het commando Allow In 99% van de standen. Maar het is handig als u crawlers geen toegang wilt geven tot een map en de bijbehorende submappen, maar wel toegang wilt geven tot een specifieke submap.
U kunt regels toevoegen door eerst de user-agent te selecteren waarop de regel van toepassing moet zijn en vervolgens met behulp van de twee tags aan te geven welke regels van toepassing moeten zijn weigeren و Allow. Er zijn ook enkele andere commando's zoals: Crawlvertraging و Sitemap , maar dit zijn ofwel:
- Het wordt door de meeste grote crawlers genegeerd of op totaal verschillende manieren geïnterpreteerd (in het geval van: Crawlvertraging).
- Ze werden extra vanwege tools zoals Google Search Console (voor het geval Sitemap)
Laten we enkele specifieke gebruiksscenario's doornemen om u te laten zien hoe al deze opdrachten samen kunnen worden gebruikt.
Robots.txt gebruiken om de toegang tot uw hele site te blokkeren
Stel dat u wilt voorkomen dat alle crawlers toegang krijgen tot uw site. Dit zal waarschijnlijk niet gebeuren op een actieve site, maar is nuttig voor een site in ontwikkeling. Om dit te doen, voeg je deze code toe aan je robots.txt-bestand:
User-agent: * Disallow: /
Wat gebeurt er in deze code?
asterisk * Naast Gebruikersagent Middelen "Alle user-agents. Het sterretje is een jokerteken, wat betekent dat deze commando's van toepassing zijn op alle user agents. De schuine streep geeft aan: / gelegen naast weigeren geeft aan dat u de toegang tot alle pagina's met "uwdomein.com/(Dit betekent alle pagina's op uw site).
Robots.txt gebruiken om te voorkomen dat een enkele crawler toegang krijgt tot uw site
Laten we de zaken veranderen. In dit voorbeeld doen we alsof u het niet leuk vindt dat Bing uw pagina's crawlt. U bent een fan van de zoekmachine van Google en wilt niet eens dat Bing naar uw site kijkt. Om te voorkomen dat alleen Bing uw site crawlt, moet u het sterretje vervangen * ب Bingbot:
User-agent: Bingbot Disallow: /
Kortom, de bovenstaande code geeft aan om een regel toe te passen weigeren Alleen op crawlers die de user-agent gebruiken "Bingbot". Nu is het onwaarschijnlijk dat u de toegang van Bing wilt blokkeren, maar dit scenario is handig als een specifieke crawler die u niet wilt, toegang heeft tot uw site. Deze site heeft een goede lijst van de meeste namen User-agents bekend.
Hoe Robots.txt te gebruiken om de toegang tot een specifieke map of bestand te blokkeren
Laten we in dit voorbeeld zeggen dat u alleen de toegang tot een specifiek bestand of map (en alle submappen van die map) wilt blokkeren. Laten we zeggen dat u beide wilt blokkeren om dit op uw site toe te passen:
- Hele wp-admin map
- wp-login.php صفحة pagina
U kunt de volgende opdrachten gebruiken:
User-agent: * Disallow: /wp-admin/ Disallow: /wp-login.php
Hoe het Robots.txt-bestand te gebruiken om toegang te verlenen tot een specifiek bestand in een map die niet is toegestaan
Welnu, laten we zeggen dat u een hele map wilt blokkeren, maar toch toegang wilt geven tot een specifiek bestand in die map. Hier komt het binnen Allow bruikbaar. Het is eigenlijk een levensvatbaar proces op uw site. In feite wordt het standaard robots.txt-bestand weergegeven in WordPress Dit is ideaal:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php
Deze code verhindert toegang tot de hele map / Wp-admin / behalve bestand /wp-admin/admin-ajax.php.
Robots.txt gebruiken om te voorkomen dat bots de zoekresultaten van uw site crawlen
Een van de wijzigingen die u aan uw site wilt aanbrengen, is om te voorkomen dat de zoekcrawler toegang krijgt tot de pagina's met zoekresultaten van uw site. WordPress gebruikt standaard de queryparameter “?s =Geeft de zoekresultaten weer. Dus om toegang te voorkomen, hoef je alleen maar de volgende regel toe te voegen:
User-agent: * Disallow: /?s= Disallow: /search/
Dit kan een effectieve manier zijn om 404-fouten te stoppen als u er veel tegenkomt.
Verschillende regels maken voor verschillende crawlers in het robots.txt-bestand
Tot nu toe hebben alle voorbeelden één regel tegelijk behandeld. Maar wat als u verschillende regels wilt toepassen op verschillende crawlers? U hoeft alleen maar elke set regels toe te voegen onder de user-agentdeclaratie van elke crawler. Als u bijvoorbeeld één regel wilt maken die van toepassing is op alle crawlers en een andere regel die van toepassing is op: Bingbot Gewoon, je kunt het als volgt doen:
User-agent: * Disallow: /wp-admin/ User-agent: Bingbot Disallow: /
In dit voorbeeld wordt de toegang voor alle crawlers geblokkeerd / Wp-admin , maar Bingbot krijgt geen toegang tot uw hele site.
Handige robots.txt-regels
Hier zijn enkele nuttige en veelvoorkomende robots.txt-regels:
| Voorbeeld | Al Qaeda |
User-agent: * Disallow: / | Voorkom het crawlen van de hele website. Houd er rekening mee dat in sommige gevallen URL's van een website nog steeds kunnen worden geïndexeerd, zelfs als ze niet zijn gecrawld. Opmerking: deze regel komt niet overeen met de verschillende AdsBot-crawlers, die expliciet moeten worden ingesteld. |
User-agent: * Disallow: /calendar/ Disallow: /junk/ | Voorkom het crawlen van een map en de inhoud ervan door een schuine streep achter de naam van de map toe te voegen. Houd er rekening mee dat u geen robots.txt-bestand moet gebruiken om de toegang tot privé-inhoud te blokkeren en we raden u aan in plaats daarvan de juiste authenticatie te gebruiken. URL's die zijn geblokkeerd door robots.txt kunnen nog steeds worden geïndexeerd zonder te worden gecrawld en iedereen kan het robots.txt-bestand bekijken, waardoor de locatie van privé-inhoud kan worden onthuld waarvan u niet wilt dat iemand anders deze ziet. |
User-agent: Googlebot-news Allow: / User-agent: * Disallow: / | Toegang voor één crawler toestaan |
User-agent: Unnecessarybot Disallow: / User-agent: * Allow: / | Sta toegang toe aan alle crawlers behalve één |
User-agent: * Disallow: /private_file.html | Voorkom het crawlen van een enkele webpagina door de pagina na de schuine streep in te voegen |
User-agent: Googlebot-Image Disallow: /images/dogs.jpg | Blokkeer een specifieke afbeelding van Google Foto's: |
User-agent: Googlebot-Image Disallow: / | Blokkeer alle afbeeldingen op uw website van Google Foto's: |
User-agent: Googlebot Disallow: /*.gif$ | Voorkom het crawlen van bestanden van een bepaald type (bijv. .gif): |
User-agent: * Disallow: / User-agent: Mediapartners-Google Allow: / | Voorkomt het crawlen van de hele site, maar geeft AdSense-advertenties op die pagina's weer en blokkeert alle andere webcrawlers dan Mediapartners-Google. Hiermee worden de pagina's verborgen voor zoekresultaten, maar de webcrawler Mediapartners-Google kan de pagina's nog steeds analyseren om te bepalen welke advertenties aan uw websitebezoekers moeten worden weergegeven. |
User-agent: Googlebot Disallow: /*.xls$ | Om URL's die eindigen op een specifieke tekenreeks te matchen, kunt u $ gebruiken. Het codevoorbeeld blokkeert bijvoorbeeld de toegang tot URL's die eindigen op .xls: |
Test uw Robots.txt-bestand
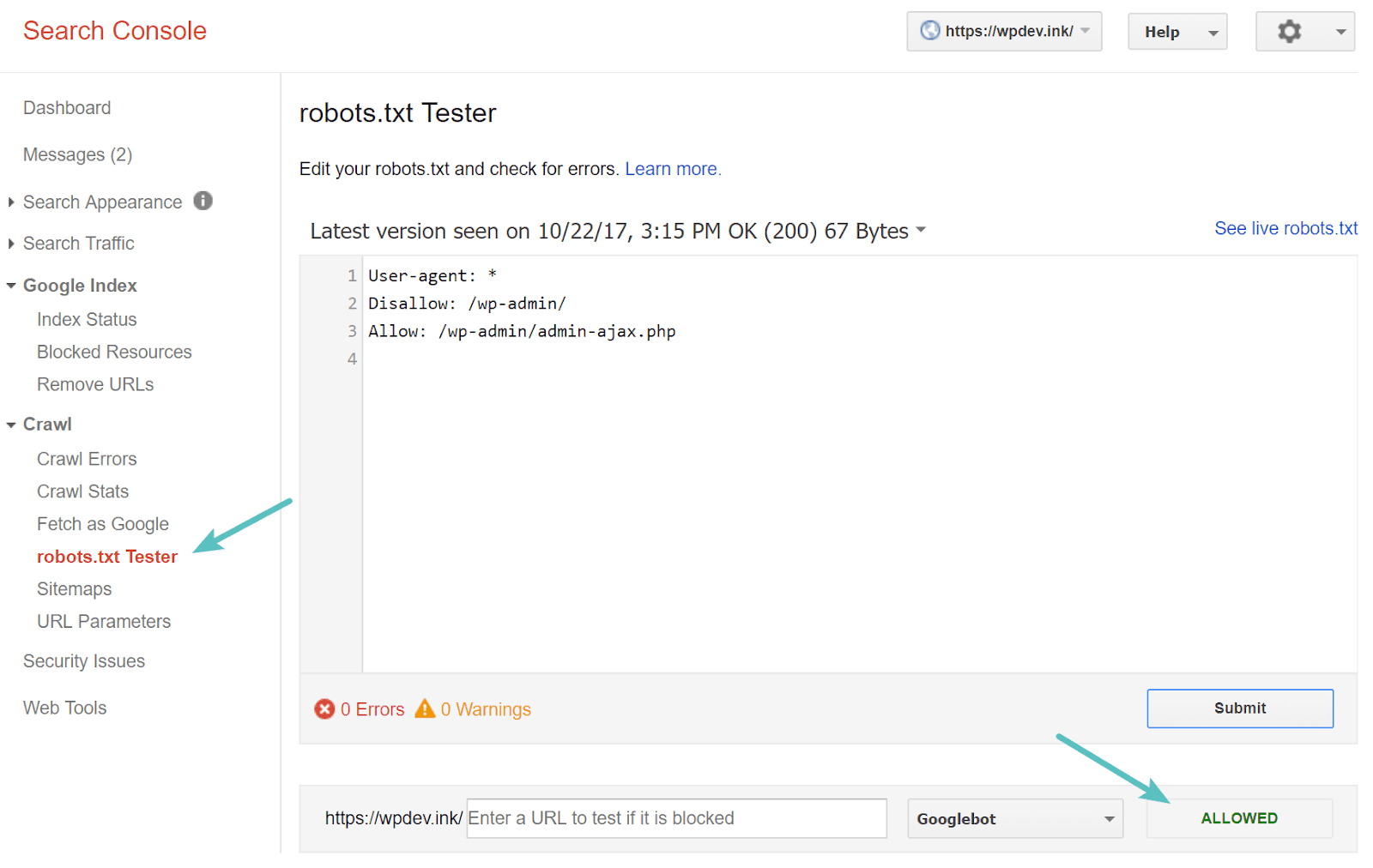
U kunt uw robots.txt-bestand testen in Google Search Console Om er zeker van te zijn dat het correct is ingesteld. Klik gewoon op uw site, en binnen "kruipen" , tik op "robots.txt-tester. U kunt vervolgens elke URL testen, inclusief uw startpagina. U zou een groen vinkje moeten zien dat zegt dat toegang is toegestaan als alles kan worden gecrawld. Je kunt ook de URL's die je hebt geblokkeerd testen om er zeker van te zijn dat ze al zijn geblokkeerd of niet zijn toegestaan.
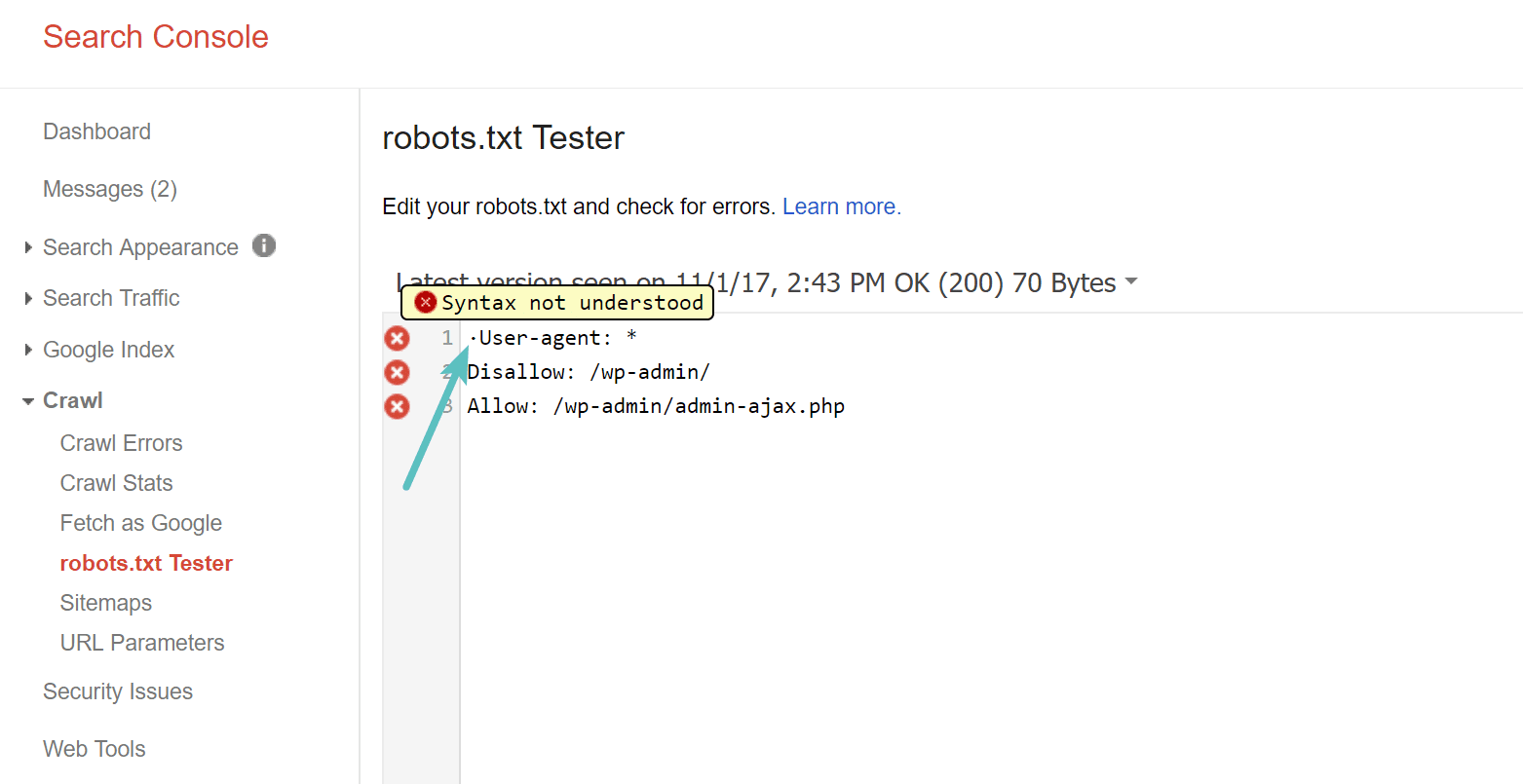
Pas op voor de UTF-8 BOM
BOM staat voor byte order mark en is in feite een onzichtbaar teken dat soms door oude teksteditors en dergelijke aan bestanden wordt toegevoegd. Als het een robots.txt-bestand overkomt, wordt het mogelijk niet correct gelezen door Google of andere zoekmachines. Daarom is het belangrijk om uw bestand te controleren op eventuele fouten. Zoals hieronder getoond, had ons bestand bijvoorbeeld een onzichtbaar karakter, wat resulteerde in een verkeerd begrip van de syntaxis door Google. Dit maakt in feite de eerste regel van het robots.txt-bestand volledig ongeldig, wat niet goed is! Glenn Gabe bevat: Uitstekend artikel Over hoe UTF-8 Bom Dood je SEO.
Googlebot bevindt zich voornamelijk in de Verenigde Staten
Het is ook belangrijk om Googlebot niet te blokkeren voor de VS, zelfs niet als u een lokaal gebied buiten de VS target. Deze bot crawlt soms lokaal, maar Googlebot bevindt zich meestal in de VS.
Welke informatie voegen populaire websites toe aan hun robots.txt-bestand
Om wat context te geven aan de bovenstaande punten, is hier hoe enkele van de meest populaire websites hun robots.txt-bestanden gebruiken.
TechCrunch
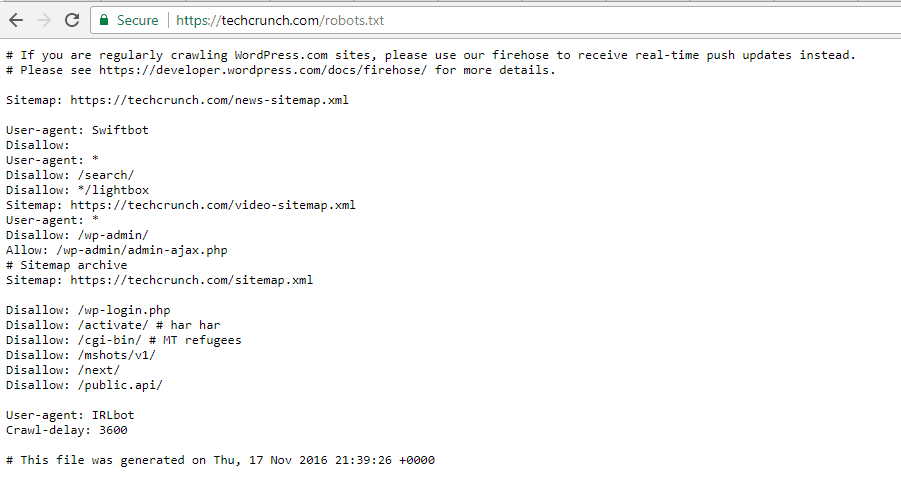
Naast het beperken van de toegang tot een aantal unieke pagina's, kan het crawlen van:
- / Wp-admin /
- /wp-login.php
Sommige crawlers hebben ook speciale beperkingen:
- snelbot
- IRLbot
Als je geïnteresseerd bent, IRLbot is een crawler van een onderzoeksproject Texas A&M University. Het is raar!
De Obama Foundation
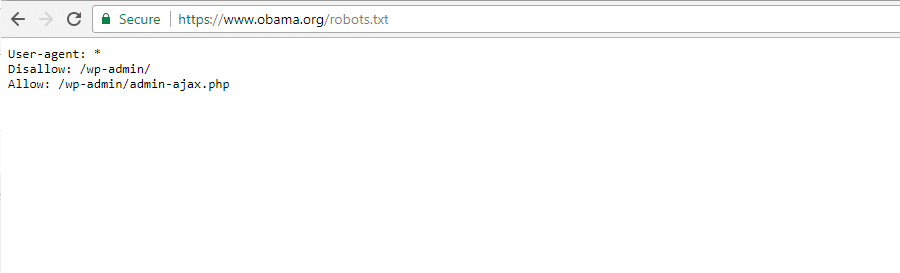
De Obama Foundation heeft geen speciale toevoegingen gedaan en heeft ervoor gekozen om uitsluitend de toegang te beperken tot: / Wp-admin /.
Boze vogels

Angry Birds heeft dezelfde standaardinstelling als The Obama Foundation. Er is niets bijzonders toegevoegd.
Drift

Ten slotte koos Drift Bestanden selecteren Zijn sitemaps in het bestand Robots.txt, maar laat verder dezelfde standaardbeperkingen als Angry Birds.
Robots.txt op de juiste manier gebruiken
Terwijl we deze handleiding afronden, willen we u er nogmaals aan herinneren dat het gebruik van het .commando weigeren Niet zoals het gebruik van het teken noindex. Het robots.txt-bestand voorkomt crawlen, maar niet noodzakelijk indexeren. Je kunt het gebruiken om specifieke regels toe te voegen om vorm te geven aan hoe interactie met de zoekmachine en andere crawlers met uw site, maar deze controleert niet expliciet of uw inhoud indexeerbaar is.
Voor de meesten WordPress-gebruikers Gewoonlijk is het niet dringend nodig om het standaard robots.txt-bestand te wijzigen. Maar als u problemen heeft met een bepaalde crawler, of als u de manier waarop zoekmachines omgaan met een bepaalde plug-in of sjabloon die u gebruikt, wilt wijzigen, wilt u misschien uw eigen regels toevoegen.
We hopen dat je deze handleiding leuk vond en laat zeker een reactie achter als je nog vragen hebt over het gebruik van je robots.txt-bestand op الويب.







