Les outils de ligne de commande comme grep et ack-grep sont parfaits pour rechercher des fichiers de texte brut pour les modèles qui correspondent à une expression régulière spécifique. Mais avez-vous déjà essayé d'utiliser ces utilitaires pour rechercher des modèles dans un fichier PDF? Okey, non! Vous n'obtiendrez aucun résultat car ces outils ne peuvent pas Rechercher des fichiers PDF. Ils ne lisent que des fichiers de texte brut.

pdfgrepIl s'agit, comme son nom l'indique, d'un petit outil de ligne de commande qui permet de rechercher du texte dans un fichier PDF sans ouvrir le fichier. La recherche est incroyablement rapide - plus rapide que la recherche fournie par presque tous les lecteurs PDF. Une grande différence entre grep et pdfgrep est que pdfgrep fonctionne sur les pages, tandis que grep fonctionne sur les lignes. Il imprime également une ligne plusieurs fois si plus d'une phrase est trouvée sur cette ligne. Regardons exactement comment utiliser l'outil.
Composition
Pour Ubuntu et d'autres distributions Linux basées sur Ubuntu, elles sont très simples:
sudo apt install pdfgrep
Pour d'autres distributions, juste en fournissant pdfgrep Comme entrée dans le gestionnaire de paquets, Qui doit être obtenu et installé. Vous pouvez également consulter la page du projet à l'adresse gitlab ce, Si vous voulez jouer avec votre code.
Lancer le test
Maintenant que l'outil est installé, allons lancer le test. La commande pdfgrep prend cette forme:
pdfgrep [OPTION...] PATTERN [FILE...]
- OPTION est une liste d'attributs de commande supplémentaires tels que -i ou -ignore-case, qui ignorent à la fois la distinction entre le modèle normal spécifié et l'heure à laquelle il a été mis en correspondance dans le fichier.
- PATTERN est juste une expression régulière étendue.
- FILE est simplement le nom du fichier, s'il se trouve dans le même répertoire de travail, ou le chemin d'accès au fichier.
J'ai exécuté la commande sur la documentation officielle de Python 3.6. L'image suivante est le résultat.
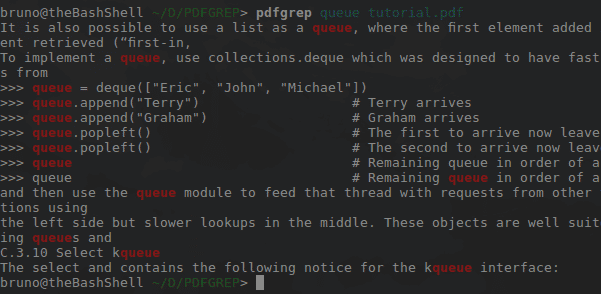
La ligne rouge indique tous les endroits où le mot "queue" apparaît. Passez -i en tant qu'option pour la commande de mots contenant le mot "File d'attente". Rappelez-vous que peu importe quand le problème est passé -i en tant qu'option.
Ajouts
pdfgrep a un grand nombre d'options intéressantes à utiliser. Cependant, vous n'en couvrirez que quelques-uns ici.
Une liste complète des options prises en charge se trouve dans les pages du manuel ou dans Guide PDFgrep en ligne. Sans oublier que pdfgrep peut rechercher plusieurs fichiers en même temps, au cas où vous travaillez avec des fichiers en vrac. La couleur de surbrillance par défaut peut être modifiée en modifiant la variable d'environnement GREP_COLORS.
Conclusion
La prochaine fois que vous songez à ouvrir un fichier PDF pour rechercher quoi que ce soit. Vous pouvez penser à utiliser pdfgrep. Le gadget est pratique et vous fera gagner du temps.