Python a acquis une réputation pour sa polyvalence et son inclusion de nombreux outils, ce qui en fait le langage de choix pour la science des données. Il a encouragé de nombreuses bibliothèques à innover dans ce domaine. Pour améliorer vos compétences et explorer de nouvelles opportunités, il est important de rester à jour avec les outils émergents et nouvellement développés.
La science des données est devenue un domaine de plus en plus important ces dernières années, en partie parce que de nouveaux outils puissants sont disponibles pour faciliter la collecte et l'analyse des données. Il existe de nombreux outils de science des données disponibles dans Python, qui peuvent être utilisés pour effectuer diverses tâches, notamment la création de graphiques, de prédictions et de visualisations prospectives. Vérifier Façons de rester au courant des dernières tendances en science des données.

1. ConnectorX : Simplifiez le téléchargement des données
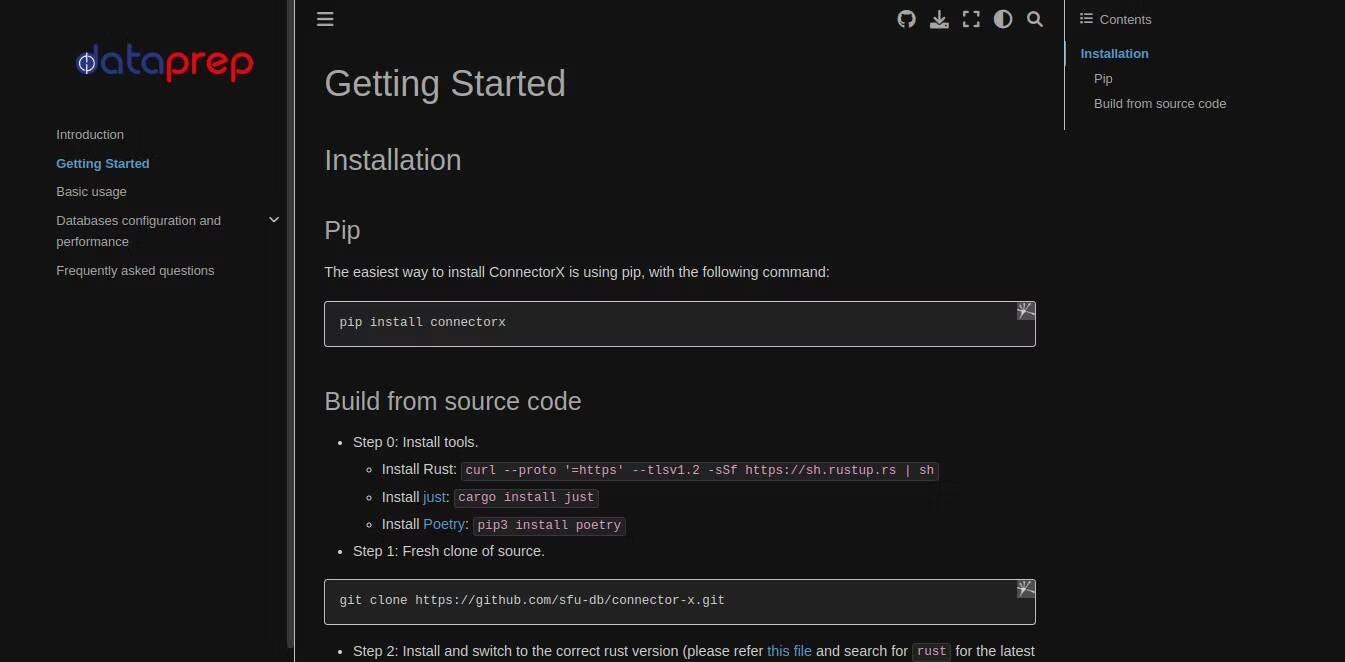
Alors que la plupart des données résident dans des bases de données, les calculs se produisent généralement en dehors de celles-ci. Cependant, le déplacement de données vers et depuis des bases de données pendant le travail réel peut entraîner des ralentissements.
Le ConnecteurX Il charge les données des bases de données dans de nombreux outils d'analyse de données populaires en Python et maintient les choses rapides et fluides en réduisant la quantité de travail à effectuer.
ConnectorX utilise la bibliothèque de langage de programmation Rust en son cœur. Cela permet des améliorations telles que la possibilité de charger à partir de la source de données en parallèle avec le partitionnement. Les données d'une base de données PostgreSQL, par exemple, vous pouvez les charger de cette façon en spécifiant la colonne de section.
IConnectorX prend également en charge la lecture de données à partir de diverses bases de données, notamment MySQL/MariaDB, SQLite, Amazon Redshift, Microsoft SQL Server, Azure SQL et Oracle.
Vous pouvez convertir les résultats en Pandas ou PyArrow DataFrames, ou les transmettre à Modin, Dask ou Polars à l'aide de PyArrow.
2. DuckDB : Activer les charges de travail de requête d'analyse
Utilisé CanardDB Stockez les données verticalement et optimisez les charges de travail de requêtes d'analyse de longue durée. Fournit toutes les fonctionnalités que vous attendez d'une base de données traditionnelle, y compris les transactions ACID.
De plus, vous pouvez le configurer dans un environnement Python avec une commande installer pip Premièrement, éliminant le besoin de configurer une suite d'applications distincte.
DuckDB ingère des données au format CSV, JSON ou Parquet. DuckDB améliore l'efficacité en divisant les bases de données résultantes en fichiers physiques séparés selon des clés telles que l'année et le mois.
Lorsque DuckDB est utilisé pour interroger, il se comporte comme une base de données relationnelle SQL normale, mais avec des fonctionnalités supplémentaires telles que l'échantillonnage aléatoire des données et la génération de fonctions analytiques (fonction cadre).
En outre, DuckDB fournit des formats utiles tels que la recherche en texte intégral, l'importation/exportation Excel, les connexions directes à SQLite et PostgreSQL, l'exportation de fichiers Parquet et la prise en charge de nombreux formats et types de données géospatiales populaires. Vérifier Comment fonctionnent les tables temporaires SQL Server ?.
3. Optimus : Simplifiez le traitement des données

Le nettoyage et la préparation des données pour les projets centrés sur DataFrame peuvent être une tâche stressante qui nécessite beaucoup d'efficacité. Optimus Il s'agit d'une boîte à outils complète conçue pour charger, explorer, nettoyer et réécrire des données dans diverses sources de données.
Optimus peut utiliser Pandas, Dask, CUDF (et Dask + CUDF), Vaex ou Spark comme moteur de données principal. Vous pouvez charger et enregistrer dans Arrow, Parquet, Excel et diverses sources de bases de données populaires, ou des formats de fichiers plats tels que CSV et JSON.
Semblable à l'API de traitement de données d'Optimus Pandas, mais fournit plus de connecteurs .Lignes() et cols(). Ces connecteurs facilitent grandement l'exécution de diverses tâches.
Par exemple, vous pouvez trier ou filtrer l'infrastructure de gestion des données en fonction des valeurs de colonne, modifier les données à l'aide de critères spécifiques ou limiter les opérations en fonction de certaines conditions. De plus, Optimus inclut des assistants conçus pour gérer les types de données courants du monde réel tels que les adresses e-mail et les URL.
Il est important de réaliser qu'Optimus est actuellement en développement actif et que sa dernière version officielle remonte à 2020. Par conséquent, il peut être moins à jour que les autres composants de votre collection. Vérifier Apprenez gratuitement l'analyse de données : les meilleurs sites Web.
4. Polars : cadre de gestion accélérée des données

Si vous travaillez avec des frameworks de gestion de données et que vous êtes frustré par les limitations de performances de Pandas, Polaires C'est une excellente solution. Cette bibliothèque de framework de données pour Python fournit une syntaxe pratique comme Pandas.
Contrairement à Pandas, Polars utilise une bibliothèque écrite en Rust qui étend les capacités de votre appareil. Vous n'avez pas besoin d'utiliser une syntaxe spéciale pour profiter des fonctionnalités d'amélioration des performances telles que le traitement parallèle ou SIMD.
Même les opérations simples comme la lecture d'un fichier CSV sont plus rapides. De plus, Polars fournit des modes d'exécution avancés et complets, permettant une exécution immédiate des requêtes ou un report si nécessaire.
Il fournit également une API de streaming pour gérer les requêtes incrémentielles, bien que cette fonctionnalité ne soit pas encore disponible pour toutes les fonctionnalités. Les développeurs Rust peuvent également créer leurs propres modules complémentaires Polars à l'aide de pyo3.
5. Snakemake : automatisez les workflows de science des données

La mise en place de flux de travail de science des données présente de nombreux défis divers, et assurer la cohérence et la prévisibilité peut être plus difficile. Il traite Faire des serpents Cette limitation est due à l'automatisation des paramètres d'analyse des données dans Python, garantissant des résultats cohérents pour tout le monde.
De nombreux projets actuels de science des données sont basés sur Snakemake. Alors que les flux de travail de science des données deviennent de plus en plus complexes, l'automatisation avec Snakemake s'avère pratique.
Le flux de travail de Snakemake est similaire à GNU. Vous pouvez spécifier les résultats souhaités à l'aide de règles qui définissent l'entrée, la sortie et les commandes nécessaires. Vous pouvez créer des règles de workflow multithread pour tirer parti du traitement parallèle.
De plus, les données de configuration peuvent provenir de fichiers JSON/YAML. Les workflows permettent également de définir des fonctions de transformation des données utilisées dans les règles et d'enregistrement des actions réalisées à chaque étape.
Snakemake conçoit des tâches portables et déployables dans des environnements gérés par Kubernetes ou certaines plateformes cloud telles que Google Cloud Life Sciences ou Tibanna sur AWS.
Vous pouvez geler les flux de travail pour utiliser un ensemble granulaire de packages, et l'exécution des flux de travail peut stocker les tests unitaires créés avec eux. Pour l'archivage de forme longue, vous pouvez stocker les workflows sous forme de fichiers zip. Vérifier Éthique des données : le code de conduite que tout scientifique des données doit suivre.
Outils de science des données inégalés pour Python
En adoptant ces derniers outils de science des données, vous pouvez augmenter votre productivité, étendre vos capacités et vous lancer dans des voyages passionnants axés sur les données. Cependant, n'oubliez pas que le paysage de la science des données évolue. Pour garder une longueur d'avance, continuez d'explorer, d'expérimenter et de vous adapter aux nouveaux outils et technologies qui émergent dans ce domaine en pleine évolution. Vous pouvez voir maintenant Comment devenir un spécialiste de la saisie de données.